
У короткому : Розмовний асистент Meta AI є найбільш нав'язливим у зборі персональних даних, перевершуючи Google Gemini, згідно з дослідженням Surfshark. Meta AI збирає 32 типи даних з 35 проаналізованих, включаючи чутливу інформацію, таку як сексуальна орієнтація, релігійні переконання та біометричні дані, тоді як інші додатки, такі як ChatGPT від OpenAI, використовують більш обережний підхід.
Зміст
Surfshark, фахівець із кібербезпеки, нещодавно опублікував оновлення свого порівняльного дослідження щодо збору персональних даних основними чат-ботами на ринку. Аналіз безапеляційний: Meta AI - це найбільш нав'язливий розмовний асистент. З 32 типами зібраних даних з 35 проаналізованих, він значно перевищує середній показник (13 типів даних) і тепер випереджає Google Gemini, який до цього займав перше місце.
З 2010-х років великі платформи будували своє домінування на монетизації уваги (цільова реклама, алгоритми рекомендацій). З появою генеративного ШІ формується нова парадигма: не просто захоплювати увагу, але взаємодіяти безпосередньо з користувачем у все більш персоналізованих і контекстуальних просторах.
Meta, інтегруючи свого асистента до екосистеми Facebook/Instagram, робить новий крок у використанні даних. Згода користувача, часто розмита в складних інтерфейсах і непрозорих політиках конфіденційності, здається все більш символічною.
Meta AI, найбільш жадібний до даних
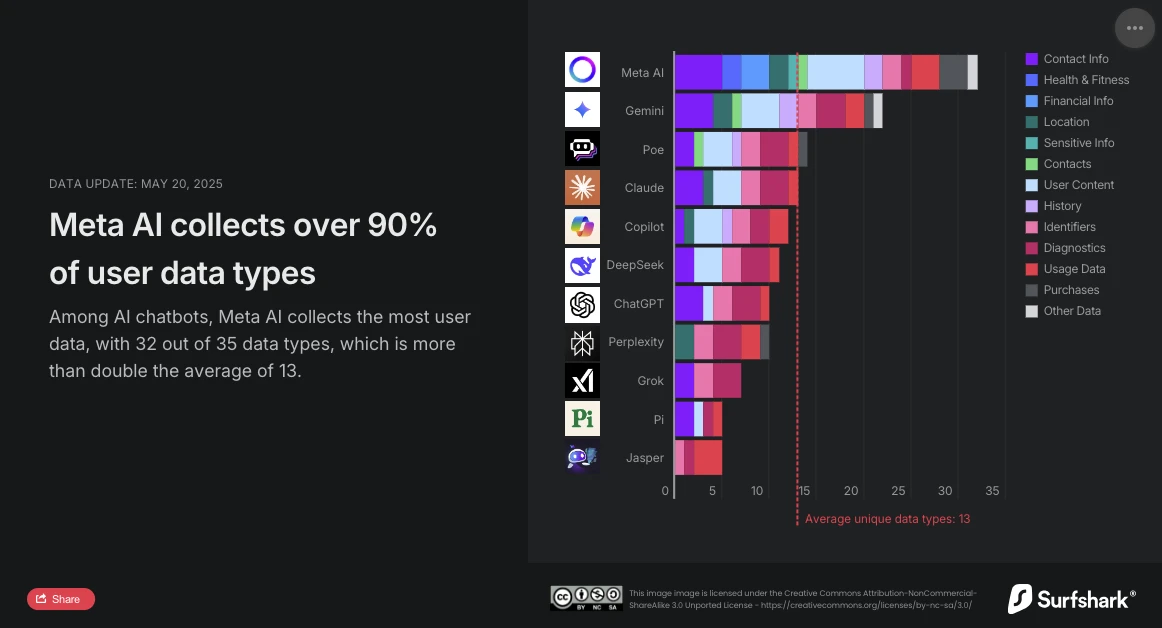
Дослідження Surfshark підкреслює обсяг збору даних чат-ботами ШІ: всі проаналізовані додатки збирають дані користувачів, 45% збирають геолокацію, і майже 30% (зокрема Jasper, Poe і Copilot) здійснюють рекламний трекінг, тобто об'єднують дані з іншими сервісами або продають їх data brokers.
Data brokers - це компанії, що спеціалізуються на купівлі та продажу персональних даних. Вони збирають інформацію з додатків, вебсайтів і публічних баз даних, щоб створити детальні профілі користувачів, які потім продаються рекламодавцям, страховикам, роботодавцям, а іноді навіть державним органам.
Серед найбільших компаній у цій галузі - Acxiom, Experian, Epsilon і Oracle Data Cloud, які обертають мільярди доларів на використанні цієї інформації. Незважаючи на зростаюче регулювання в деяких регіонах, ринок залишається слабо контрольованим у глобальному масштабі.
Згідно з дослідженням, Meta AI єдиний, хто збирає дані про фінансову інформацію, здоров'я та фізичну форму. Додаток на цьому не зупиняється: він також єдиний, хто збирає особливо чутливу інформацію: расові або етнічні дані, сексуальна орієнтація, інформація про вагітність або пологи, інвалідність, релігійні або філософські переконання, членство в профспілці, політичні погляди, генетична інформація або біометричні дані.
Мауд Лепеті, керівник у Франції в Surfshark, попереджає:
"Meta не обмежується збором даних через Facebook, Instagram або свою Audience Network. Сьогодні вони застосовують ту ж логіку до свого асистента ШІ, підживлюючи його публічними повідомленнями, фотографіями, повідомленнями... але також даними, введеними безпосередньо в інтерфейс. Це нова демонстрація можливих відхилень, коли генеративний ШІ базується на персональних даних без захисних бар'єрів".
Meta AI також єдиний разом з Copilot, хто збирає дані, пов'язані з ідентичністю користувача, щоб поділитися ними з третіми сторонами в рамках цільової реклами. Однак, з 24 типами використаних даних, він значно відрізняється від Copilot, який використовує лише два (ідентифікатор пристрою та рекламні дані).
ChatGPT, стратегія поміркованості
OpenAI дотримується більш обережного підходу. Зі всього 10 типами зібраних даних, серед яких контактні дані, вміст користувача, дані використання та діагностики, ChatGPT не використовує рекламний трекінг і не ділиться даними з третіми сторонами для комерційних цілей. Крім того, опція "тимчасових чатів", які видаляються через 30 днів, пропонує цікавий компроміс між безперервністю обслуговування та повагою до приватності. Його користувачі також можуть вимагати від OpenAI видалення своїх даних для навчання своїх моделей.
DeepSeek, між уявною скритністю та реальними ризиками
Китайське рішення DeepSeek займає середню позицію з 11 типами зібраних даних, включаючи історію чатів. Однак місце зберігання даних (Китайська Народна Республіка) та велике порушення безпеки, про яке повідомляє The Hacker News (витік понад мільйона записів розмов), нагадують, що місцезнаходження серверів та практики кібербезпеки мають таке ж значення, як і кількість зібраних даних.
Дані європейських користувачів, що експлуатуються Meta з цього тижня
Поки Meta збирається розпочати збір даних у Франції та Європі вже з 27 травня для навчання своїх моделей ШІ, Мауд Лепеті нагадує:
"На відміну від людини, генеративний ШІ не звітує. Він може навчитися чому завгодно, але не може розучитися. Те, що ви вводите в чат-бот, залишається в його системі, потенційно назавжди".
Якщо ви не згодні з використанням ваших персональних даних Meta, ви повинні висловити свою незгоду до цієї дати. Їхній підхід, що базується на принципі "opt-out", де користувач повинен висловити своє незгоду, замість явної згоди ("opt-in"), викликає питання щодо його відповідності GDPR. Законний інтерес, на який посилається Meta, щоб виправдати цей збір без попередньої згоди, привів NYOB та споживчі асоціації до подальших дій проти компанії. CNIL, зі свого боку, вважає, що використання законного інтересу як правової основи для навчання системи ШІ не є незаконним сам по собі, але вимагає ретельної оцінки інтересів і фундаментальних прав осіб.
Краще зрозуміти
Що таке GDPR і як він застосовується до практик збору даних Meta AI?
GDPR (Загальний регламент захисту даних) - це регламент ЄС, спрямований на захист персональних даних. Він вимагає явної згоди ('opt-in') на збір і використання даних. У випадку з Meta AI, яка використовує згоду 'opt-out', існують дебати щодо відповідності GDPR, що призвело до судових дій.
Як використовується концепція 'законного інтересу' в регулюванні персональних даних?
'Законний інтерес' є юридичною основою під GDPR для обробки даних без явної згоди. Компанії повинні показати, що їхні законні інтереси не перевищують фундаментальні права осіб. Це суперечлива основа, оскільки її застосування залежить від збалансованої оцінки, яка може бути суб'єктивною.