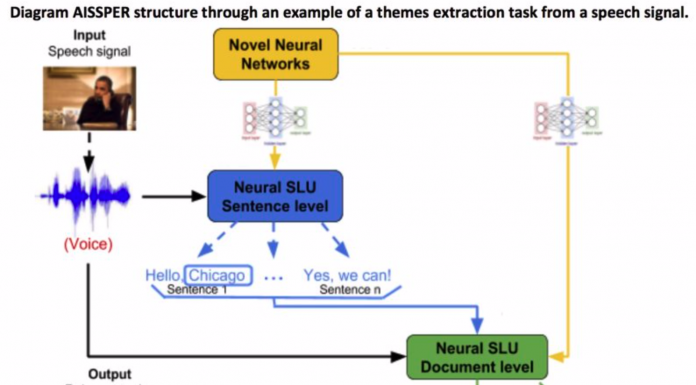
La compréhension du langage naturel (Natural Language Understanding, NLU) constitue un sous-domaine de l'intelligence artificielle centré sur l'interprétation et l'analyse du langage humain par les machines. Elle vise à permettre aux systèmes informatiques de saisir non seulement la signification littérale des textes ou des paroles, mais aussi les subtilités contextuelles, les intentions, l'implicite et les ambiguïtés inhérentes au langage naturel. Contrairement à la simple reconnaissance de texte (comme l'extraction de mots-clés), la NLU implique une modélisation sémantique et pragmatique, permettant une interaction plus « intelligente » entre humains et machines.
Cas d'usages et exemples d'utilisation
La compréhension du langage naturel est fondamentale pour des applications comme les chatbots, les assistants virtuels, l'analyse de sentiments, la classification de documents, la détection d'intentions dans les requêtes client, ou encore la génération automatique de réponses. Elle est également utilisée dans la traduction automatique, la recherche d'information intelligente, et la modération de contenu.
Par exemple, dans le service client, les systèmes NLU identifient précisément le motif de contact et orientent la réponse. Dans le secteur médical, ils analysent des notes cliniques pour extraire des informations pertinentes.
Principaux outils logiciels, librairies, frameworks, logiciels
Parmi les outils les plus utilisés figurent spaCy, NLTK, Stanford NLP, Rasa NLU, AllenNLP et les API d'IBM Watson et de Google Cloud Natural Language. Les modèles pré-entraînés tels que BERT, RoBERTa, GPT et T5 sont devenus des standards pour le développement avancé de solutions NLU.
Derniers développements, évolutions et tendances
La NLU a connu une avancée majeure avec l'avènement des modèles de langage de grande taille (LLM), qui atteignent des niveaux de compréhension contextuelle et de généralisation inédits. Les tendances actuelles incluent l'utilisation de l'apprentissage par transfert, le raffinement de modèles multilingues, ainsi que l'intégration de connaissances externes pour réduire les biais et améliorer la robustesse. Le défi actuel demeure dans l'explicabilité des modèles et leur adaptation à des domaines spécifiques avec peu de données annotées.