
Em resumo : O assistente conversacional Meta AI é o mais intrusivo em matéria de coleta de dados pessoais, superando o Google Gemini, segundo um estudo da Surfshark. Meta AI coleta 32 tipos de dados dos 35 analisados, incluindo informações sensíveis como orientação sexual, crenças religiosas e dados biométricos, enquanto outros aplicativos como ChatGPT da OpenAI adotam uma abordagem mais cautelosa.
Índice
Surfshark, especialista em cibersegurança, publicou recentemente uma atualização de seu estudo comparativo sobre a coleta de dados pessoais pelos principais chatbots do mercado. A análise é clara: Meta AI é o assistente conversacional mais intrusivo. Com 32 tipos de dados coletados dos 35 analisados, supera amplamente a média (13 tipos de dados) e agora ultrapassa o Google Gemini, que até então ocupava o primeiro lugar.
Desde os anos 2010, as grandes plataformas construíram sua dominação na monetização da atenção (publicidade direcionada, algoritmos de recomendação). Com o advento da IA generativa, um novo paradigma surge: não mais capturar a atenção, mas interagir diretamente com o usuário em espaços cada vez mais personalizados e contextuais.
Meta, ao integrar seu assistente ao ecossistema Facebook/Instagram, ultrapassa um limite na exploração de dados. O consentimento do usuário, muitas vezes diluído em interfaces complexas e políticas de privacidade opacas, parece cada vez mais simbólico.
Meta AI, o mais ávido por dados
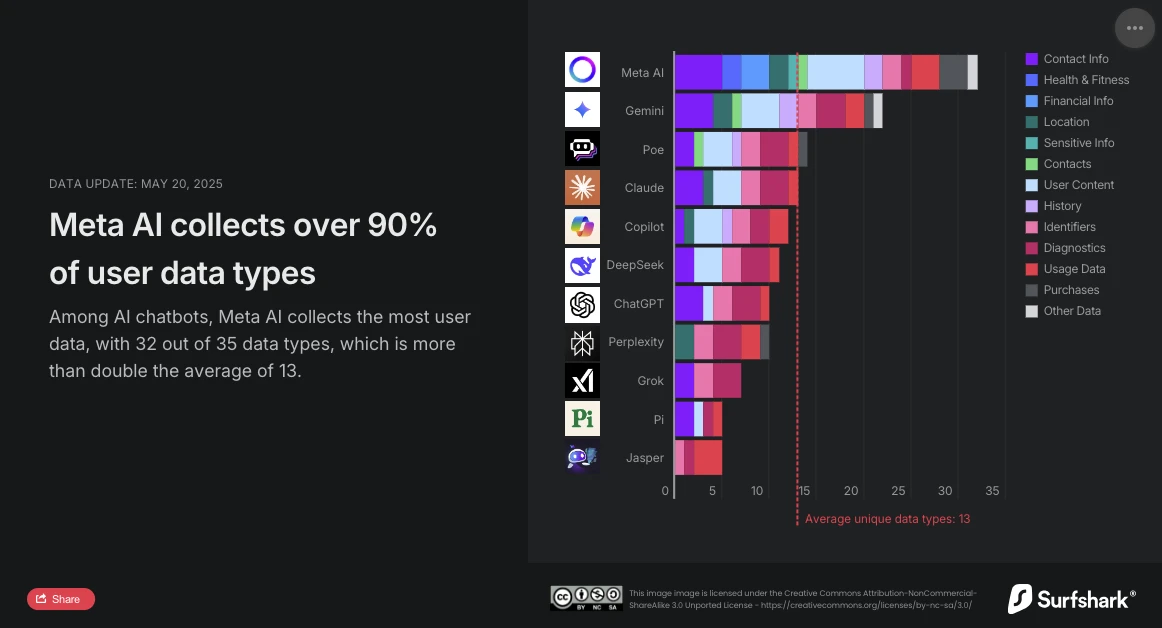
O estudo da Surfshark destaca a extensão da coleta de dados pelos chatbots de IA: todos os aplicativos analisados coletam dados do usuário, 45% coletam geolocalização, e quase 30% (notadamente Jasper, Poe e Copilot) praticam o rastreamento publicitário, ou seja, cruzam os dados com os de outros serviços ou os vendem para corretores de dados.
Os corretores de dados são empresas especializadas na compra e venda de dados pessoais. Elas compilam informações de aplicativos, sites web e bases de dados públicas para criar perfis detalhados dos usuários, vendidos posteriormente para anunciantes, seguradoras, empregadores, e às vezes até para organismos públicos.
Entre as maiores empresas do setor, estão Acxiom, Experian, Epsilon e Oracle Data Cloud, que movimentam bilhões de dólares explorando essas informações. Apesar de uma regulamentação crescente em algumas regiões, o mercado permanece pouco regulamentado em escala global.
Segundo o estudo, Meta AI é o único a coletar dados sobre informações financeiras, saúde e condição física. O aplicativo não para por aí: ele também é o único a coletar informações particularmente sensíveis: dados raciais ou étnicos, orientação sexual, informações sobre gravidez ou parto, deficiência, crenças religiosas ou filosóficas, filiação sindical, opiniões políticas, informações genéticas ou dados biométricos.
Maud Lepetit, responsável na França pela Surfshark, alerta:
"Meta não se contenta em aspirar dados via Facebook, Instagram ou sua Audience Network. Hoje, eles aplicam a mesma lógica ao seu assistente de IA, alimentando-o com publicações públicas, fotos, mensagens... mas também com os dados inseridos diretamente na interface. É uma nova demonstração dos desvios possíveis quando a IA generativa se baseia em dados pessoais sem salvaguardas".
Meta AI também é o único, junto com Copilot, a coletar dados relacionados à identidade do usuário para compartilhá-los com terceiros no contexto de publicidade direcionada. No entanto, com 24 tipos de dados explorados, distingue-se nitidamente do Copilot, que utiliza apenas dois (ID de dispositivo e dados publicitários).
ChatGPT, uma estratégia de moderação
OpenAI adota uma abordagem mais cautelosa. Com apenas 10 tipos de dados coletados, entre os quais dados de contato, conteúdo do usuário, dados de uso e diagnóstico, o ChatGPT não recorre ao rastreamento publicitário nem ao compartilhamento com terceiros para fins comerciais. Além disso, a opção de "chats temporários", apagados após 30 dias, oferece um compromisso interessante entre continuidade de serviço e respeito à privacidade. Seus usuários também podem pedir para que a OpenAI apague seus dados para o treinamento de seus modelos.
DeepSeek, entre discrição aparente e riscos concretos
A solução chinesa DeepSeek posiciona-se no meio do caminho com 11 tipos de dados coletados, incluindo o histórico de chats. No entanto, o local de armazenamento dos dados (República Popular da China) e uma violação de segurança significativa relatada pelo The Hacker News (vazamento de mais de um milhão de registros de conversas) lembram que a localização dos servidores e as práticas de cibersegurança pesam tanto quanto o número de dados coletados.
Os dados dos usuários europeus explorados pela Meta a partir desta semana
Enquanto a Meta começará sua coleta de dados na França e na Europa a partir deste 27 de maio para treinar seus modelos de IA, Maud Lepetit lembra:
"Ao contrário de um humano, a IA generativa não presta contas. Ela pode aprender qualquer coisa, mas não pode desaprender. O que você insere em um chatbot permanece em seu sistema, potencialmente para sempre".
Se você se opõe à exploração de seus dados pessoais pela Meta, deve fazê-lo antes desta data limite. Sua abordagem, que se baseia no princípio do "opt-out", onde o usuário deve expressar sua recusa, em vez de um consentimento explícito ("opt-in"), levanta questões quanto à sua conformidade com o RGPD. O interesse legítimo invocado pela Meta para justificar essa coleta sem consentimento prévio levou a NYOB e associações de consumidores a continuarem suas ações contra a empresa. A CNIL, por sua vez, considera que o recurso ao interesse legítimo como base legal para treinar um sistema de IA não é ilegal por si só, mas requer uma avaliação atenta dos interesses e direitos fundamentais das pessoas envolvidas.
Para entender melhor
O que é o RGPD e como se aplica às práticas de coleta de dados da Meta AI?
O RGPD (Regulamento Geral sobre a Proteção de Dados) é uma norma da UE que visa proteger os dados pessoais dos indivíduos. Exige consentimento explícito ('opt-in') para a coleta e uso de dados. No caso da Meta AI, que utiliza consentimento por 'opt-out', há debates sobre conformidade com o RGPD, levando a ações legais.
Como é utilizado o conceito de 'interesse legítimo' na regulamentação de dados pessoais?
O interesse legítimo é uma base legal no RGPD para processar dados sem consentimento explícito. Requer que as empresas mostrem que seus interesses legítimos não prevalecem sobre os direitos fundamentais das pessoas. É uma base controversa, pois sua aplicação depende de uma avaliação equilibrada que pode ser subjetiva.