
W skrócie : Asystent konwersacyjny Meta AI jest najbardziej inwazyjny pod względem gromadzenia danych osobowych, przewyższając Google Gemini, według badania Surfshark. Meta AI gromadzi 32 typy danych na 35 analizowanych, w tym informacje wrażliwe, takie jak orientacja seksualna, przekonania religijne i dane biometryczne, podczas gdy inne aplikacje, takie jak ChatGPT od OpenAI, przyjmują bardziej ostrożne podejście.
Podsumowanie
Surfshark, specjalista ds. bezpieczeństwa cybernetycznego, niedawno opublikował aktualizację swojego badania porównawczego dotyczącego gromadzenia danych osobowych przez głównych chatbotów na rynku. Analiza jest niepodważalna: Meta AI jest najbardziej inwazyjnym asystentem konwersacyjnym. Z 32 typami zbieranych danych na 35 analizowanych, znacznie przewyższa średnią (13 typów danych) i obecnie wyprzedza Google Gemini, który dotychczas zajmował pierwsze miejsce.
Od lat 2010, wielkie platformy zbudowały swoją dominację na monetyzacji uwagi (reklama ukierunkowana, algorytmy rekomendacji). Z pojawieniem się generatywnej AI, rysuje się nowy paradygmat: nie tylko przyciągać uwagę, ale wchodzić w bezpośrednią interakcję z użytkownikiem w coraz bardziej spersonalizowanych i kontekstowych przestrzeniach.
Meta, integrując swojego asystenta z ekosystemem Facebook/Instagram, przekracza próg w eksploatacji danych. Zgoda użytkownika, często rozmyta w złożonych interfejsach i nieprzejrzystych politykach prywatności, wydaje się coraz bardziej symboliczna.
Meta AI, najbardziej łakomy na dane
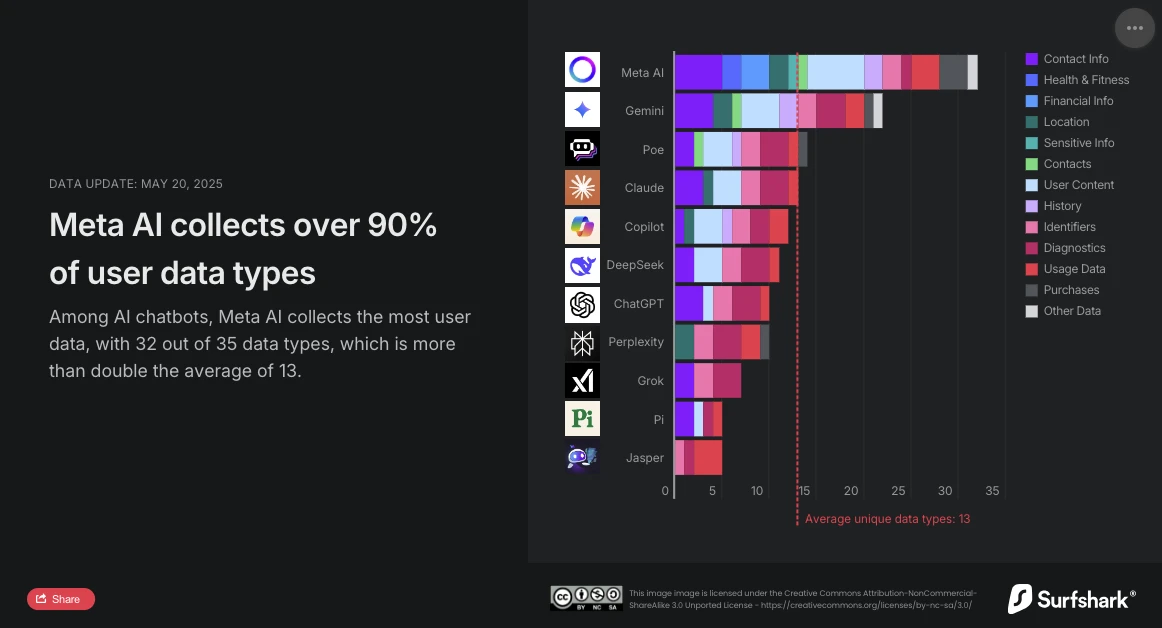
Badanie Surfshark uwydatnia rozmiar gromadzenia danych przez chatboty AI: wszystkie analizowane aplikacje zbierają dane użytkownika, 45% gromadzi dane geolokalizacyjne, a niemal 30%, (w tym Jasper, Poe i Copilot) praktykuje śledzenie reklamowe, to znaczy krzyżują dane z innymi usługami lub sprzedają je brokerom danych.
Brokerzy danych to firmy specjalizujące się w kupnie i sprzedaży danych osobowych. Kompilują informacje z aplikacji, stron internetowych i baz danych publicznych, aby tworzyć szczegółowe profile użytkowników, które następnie sprzedają reklamodawcom, ubezpieczycielom, pracodawcom, a czasem nawet organom publicznym.
Wśród największych firm w tej branży znajdują się Acxiom, Experian, Epsilon i Oracle Data Cloud, które obracają miliardami dolarów, eksploatując te informacje. Pomimo rosnących regulacji w niektórych regionach, rynek pozostaje słabo nadzorowany na poziomie globalnym.
Zgodnie z badaniem, Meta AI jest jedynym, który zbiera dane o informacjach finansowych, zdrowiu i kondycji fizycznej. Aplikacja na tym nie poprzestaje: jest również jedyną, która zbiera szczególnie wrażliwe informacje: dane rasowe lub etniczne, orientację seksualną, informacje o ciąży lub porodzie, niepełnosprawność, przekonania religijne lub filozoficzne, przynależność do związków zawodowych, opinie polityczne, informacje genetyczne lub dane biometryczne.
Maud Lepetit, szefowa Surfshark we Francji, ostrzega:
"Meta nie tylko zasysa dane przez Facebook, Instagram czy swoją sieć Audience Network. Dziś stosują tę samą logikę do swojego asystenta AI, zasilając go publicznymi postami, zdjęciami, wiadomościami... ale także danymi wprowadzonymi bezpośrednio w interfejsie. To nowy pokaz potencjalnych nadużyć, gdy generatywna AI opiera się na danych osobowych bez zabezpieczeń".
Meta AI jest również jedyną z Copilot, która zbiera dane związane z tożsamością użytkownika, aby udostępniać je osobom trzecim w ramach reklamy ukierunkowanej. Jednak z 24 typami wykorzystywanych danych wyraźnie wyróżnia się na tle Copilot, który używa tylko dwóch (ID urządzenia i dane reklamowe).
ChatGPT, strategia umiarkowania
OpenAI przyjmuje bardziej ostrożne podejście. Z zaledwie 10 typami zbieranych danych, w tym danymi kontaktowymi, treścią użytkownika, danymi użytkowania i diagnostycznymi, ChatGPT nie stosuje śledzenia reklamowego ani nie dzieli się danymi z osobami trzecimi w celach komercyjnych. Dodatkowo, opcja "czatów tymczasowych", usuwanych po 30 dniach, oferuje interesujący kompromis między ciągłością usługi a poszanowaniem prywatności. Użytkownicy mogą również poprosić OpenAI o usunięcie ich danych z treningu jego modeli.
DeepSeek, pomiędzy pozorną dyskrecją a realnymi zagrożeniami
Chińskie rozwiązanie DeepSeek znajduje się pośrodku z 11 typami zbieranych danych, w tym historią czatów. Jednak miejsce przechowywania danych (Chińska Republika Ludowa) i poważne naruszenie bezpieczeństwa zgłoszone przez The Hacker News (wyciek ponad miliona zapisów rozmów) przypominają, że lokalizacja serwerów i praktyki bezpieczeństwa cybernetycznego są równie ważne, co liczba zbieranych danych.
Dane użytkowników europejskich wykorzystywane przez Meta od tego tygodnia
Podczas gdy Meta zacznie zbierać dane we Francji i Europie już 27 maja, aby trenować swoje modele AI, Maud Lepetit przypomina:
"W przeciwieństwie do człowieka, generatywna AI nie ponosi odpowiedzialności. Może nauczyć się wszystkiego, ale nie może się oduczyć. To, co wpisujesz w chatbocie, pozostaje w jego systemie, potencjalnie na zawsze".
Jeśli sprzeciwiasz się wykorzystywaniu twoich danych osobowych przez Meta, musisz to zrobić przed tym terminem. Jego podejście, które opiera się na zasadzie "opt-out", gdzie użytkownik musi wyrazić sprzeciw, a nie na wyraźnej zgodzie ("opt-in"), budzi pytania co do jego zgodności z RODO. Prawnie uzasadniony interes, na który powołuje się Meta, aby uzasadnić to zbieranie bez uprzedniej zgody, skłonił NOYB i organizacje konsumenckie do kontynuowania działań przeciwko firmie. CNIL uważa, że powoływanie się na uzasadniony interes jako podstawę prawną do trenowania systemu AI nie jest samo w sobie nielegalne, ale wymaga starannego rozważenia interesów i podstawowych praw osób, których dane dotyczą.
Bardziej zrozumiałe
Co to jest RODO i jak ma się do praktyk zbierania danych przez Meta AI?
RODO (Ogólne Rozporządzenie o Ochronie Danych) to regulacja UE mająca na celu ochronę danych osobowych osób fizycznych. Wymaga wyraźnej zgody ('opt-in') na zbieranie i wykorzystywanie danych. W przypadku Meta AI, która używa zgody 'opt-out', istnieją debaty na temat zgodności z RODO, co prowadzi do działań prawnych.
Jak pojęcie 'uzasadnionego interesu' jest wykorzystywane w regulacji danych osobowych?
Uzasadniony interes to podstawa prawna w RODO do przetwarzania danych bez wyraźnej zgody. Wymaga od firm udowodnienia, że ich uzasadnione interesy nie naruszają podstawowych praw osób indywidualnych. Jest to kontrowersyjna podstawa, ponieważ jej zastosowanie opiera się na zrównoważonej ocenie, która może być subiektywna.