
In kort : De conversatie-assistent Meta AI is het meest indringend in termen van het verzamelen van persoonlijke gegevens, en overtreft Google Gemini, volgens een studie van Surfshark. Meta AI verzamelt 32 van de 35 geanalyseerde soorten gegevens, inclusief gevoelige informatie zoals seksuele geaardheid, religieuze overtuigingen en biometrische gegevens, terwijl andere applicaties zoals OpenAI's ChatGPT een voorzichtiger benadering hanteren.
Samenvatting
Surfshark, specialist in cybersecurity, heeft onlangs een update van zijn vergelijkende studie over de verzameling van persoonlijke gegevens door de belangrijkste chatbots op de markt gepubliceerd. De analyse laat geen twijfel: Meta AI is de meest indringende conversatie-assistent. Met 32 soorten verzamelde gegevens van de 35 geanalyseerde, ligt het ver boven het gemiddelde (13 soorten gegevens) en overtreft het nu Google Gemini, die tot nu toe de eerste plaats bekleedde.
Sinds de jaren 2010 hebben grote platforms hun dominantie opgebouwd door de aandacht te monetiseren (gerichte advertenties, aanbevelingsalgoritmen). Met de opkomst van generatieve AI tekent zich een nieuw paradigma af: niet langer de aandacht trekken, maar direct interageren met de gebruiker in steeds persoonlijkere en contextuele ruimtes.
Door zijn assistent in het Facebook/Instagram-ecosysteem te integreren, heeft Meta een grens overschreden in de exploitatie van gegevens. De toestemming van de gebruiker, vaak verdund in complexe interfaces en ondoorzichtige privacybeleid, lijkt steeds symbolischer.
Meta AI, de meest datahongerige
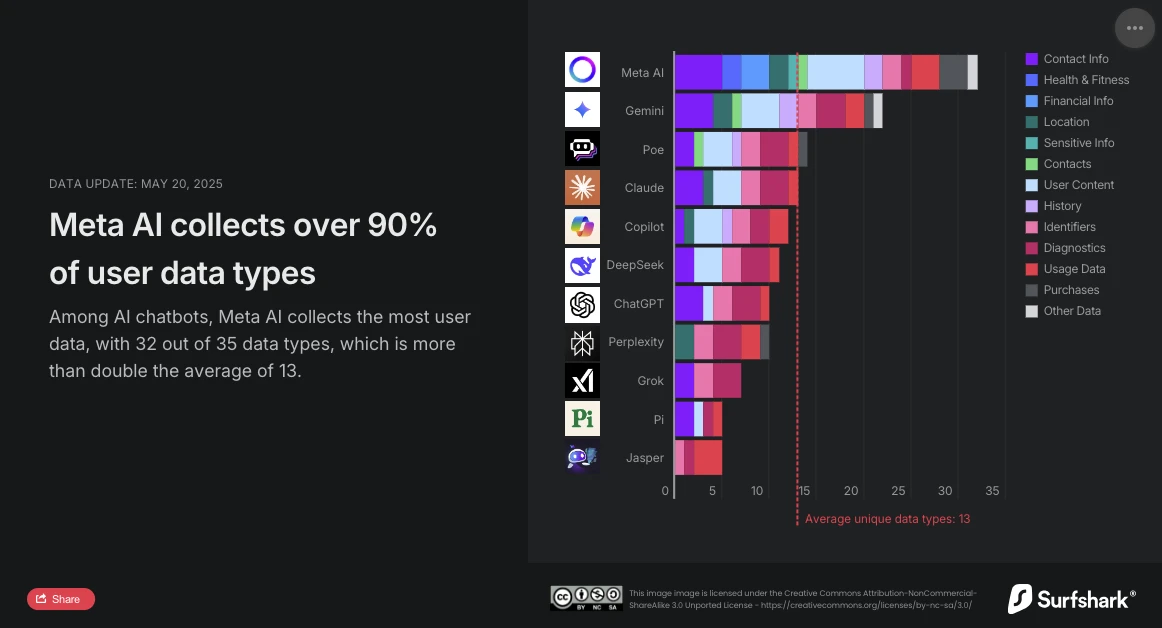
De studie van Surfshark benadrukt de omvang van de gegevensverzameling door AI-chatbots: alle geanalyseerde applicaties verzamelen gebruikersgegevens, 45% verzamelt geolocatie, en bijna 30%, (waaronder Jasper, Poe en Copilot) voeren advertentietracking uit, dat wil zeggen dat ze gegevens kruisen met die van andere diensten of ze verkopen aan databrokers.
Databrokers zijn bedrijven die gespecialiseerd zijn in de aankoop en verkoop van persoonlijke gegevens. Ze verzamelen informatie uit applicaties, websites en openbare databases om gedetailleerde gebruikersprofielen te creëren, die vervolgens worden verkocht aan adverteerders, verzekeraars, werkgevers en soms zelfs aan overheidsinstanties.
Onder de grootste bedrijven in de sector bevinden zich Acxiom, Experian, Epsilon en Oracle Data Cloud, die miljarden dollars verdienen met het exploiteren van deze informatie. Ondanks toenemende regelgeving in sommige regio's blijft de markt wereldwijd weinig gereguleerd.
Volgens de studie is Meta AI de enige die gegevens verzamelt over financiële informatie, gezondheid en fitheid. De applicatie stopt daar niet: het is ook de enige die bijzonder gevoelige informatie verzamelt: raciale of etnische gegevens, seksuele geaardheid, informatie over zwangerschap of bevalling, handicap, religieuze of filosofische overtuigingen, vakbondslidmaatschap, politieke opvattingen, genetische informatie of biometrische gegevens.
Maud Lepetit, verantwoordelijk voor Frankrijk bij Surfshark, waarschuwt:
"Meta beperkt zich niet tot het opzuigen van gegevens via Facebook, Instagram of zijn Audience Network. Vandaag passen ze dezelfde logica toe op hun AI-assistent, door deze te voeden met openbare berichten, foto's, berichten... maar ook met de gegevens die direct in de interface worden ingevoerd. Dit is een nieuwe demonstratie van de mogelijke excessen wanneer generatieve AI vertrouwt op persoonlijke gegevens zonder waarborgen".
Meta AI is ook de enige naast Copilot die gegevens verzamelt die verband houden met de identiteit van de gebruiker om ze te delen met derden in het kader van gerichte reclame. Echter, met 24 soorten geëxploiteerde gegevens onderscheidt het zich duidelijk van Copilot, dat er slechts twee gebruikt (apparaat-ID en advertentiegegevens).
ChatGPT, een strategie van moderatie
OpenAI hanteert een voorzichtiger aanpak. Met slechts 10 soorten verzamelde gegevens, waaronder contactgegevens, gebruikersinhoud, gebruiksgegevens en diagnostiek, maakt ChatGPT geen gebruik van advertentietracking noch van het delen met derden voor commerciële doeleinden. Bovendien biedt de optie van "tijdelijke chats", die na 30 dagen worden verwijderd, een interessante compromis tussen continuïteit van de dienst en respect voor privacy. Gebruikers kunnen ook vragen aan OpenAI om hun gegevens te verwijderen voor de training van zijn modellen.
DeepSeek, tussen schijnbare discretie en concrete risico's
De Chinese oplossing DeepSeek bevindt zich in het midden met 11 soorten verzamelde gegevens, waaronder chatgeschiedenis. Echter, de locatie van de gegevensopslag (de Volksrepubliek China) en een grote beveiligingsschending, gerapporteerd door The Hacker News (lek van meer dan een miljoen gespreksregistraties), herinneren eraan dat de locatie van servers en cybersecuritypraktijken net zo zwaar wegen als het aantal verzamelde gegevens.
De gegevens van Europese gebruikers worden deze week door Meta geëxploiteerd
Nu Meta vanaf 27 mei begint met het verzamelen van gegevens in Frankrijk en Europa om zijn AI-modellen te trainen, herinnert Maud Lepetit eraan:
"In tegenstelling tot een mens, legt generatieve AI geen verantwoording af. Ze kan alles leren, maar ze kan niet afleren. Wat je invoert in een chatbot blijft in zijn systeem, mogelijk voor altijd".
Als je je tegen het gebruik van je persoonlijke gegevens door Meta verzet, moet je dit doen vóór deze deadline. Hun aanpak, die berust op het "opt-out"-principe, waarbij de gebruiker zijn weigering moet uiten, in plaats van op expliciete toestemming ("opt-in"), roept vragen op over de naleving van de AVG. Het legitieme belang dat Meta inroept om deze verzameling zonder voorafgaande toestemming te rechtvaardigen, heeft NYOB en consumentenverenigingen ertoe gebracht hun acties tegen het bedrijf voort te zetten. De CNIL, van haar kant, oordeelt dat het gebruik van legitiem belang als wettelijke basis voor het trainen van een AI-systeem niet illegaal op zich is, maar een zorgvuldige evaluatie vereist van de belangen en fundamentele rechten van de betrokken personen.
Beter begrijpen
Wat is GDPR en hoe is het van toepassing op de gegevensverzamelingspraktijken van Meta AI?
GDPR (Algemene Verordening Gegevensbescherming) is een EU-verordening die gericht is op het beschermen van persoonsgegevens. Het vereist expliciete toestemming ('opt-in') voor gegevensverzameling en -gebruik. In het geval van Meta AI, dat 'opt-out'-toestemming gebruikt, zijn er discussies over GDPR-naleving, wat heeft geleid tot juridische stappen.
Hoe wordt het concept van 'gerechtvaardigd belang' gebruikt in de regulering van persoonsgegevens?
Gerechtvaardigd belang is een wettelijke basis onder de AVG voor het verwerken van gegevens zonder expliciete toestemming. Bedrijven moeten aantonen dat hun gerechtvaardigde belangen de fundamentele rechten van individuen niet overschrijden. Het is een controversiële basis omdat de toepassing ervan afhankelijk is van een evenwichtige beoordeling die subjectief kan zijn.