
TLDR : Meta AI는 Google Gemini를 능가하는 개인 데이터 수집에 있어 가장 침해적인 대화형 보조자라고 Surfshark 연구에 따르면 밝혀졌습니다. Meta AI는 35가지 중 32가지 유형의 데이터를 수집하며, 성적 지향, 종교적 신념, 생체 데이터와 같은 민감한 정보를 포함합니다. 반면, OpenAI의 ChatGPT 등 다른 애플리케이션은 보다 신중한 접근 방식을 취하고 있습니다.
목록
Surfshark, 사이버 보안 전문 기업, 최근 시장의 주요 챗봇들이 개인 데이터를 수집하는 방식에 대한 비교 연구 업데이트를 발표했습니다. 분석 결과는 명확합니다: Meta AI는 가장 침해적인 대화형 보조자입니다. 분석된 35가지 데이터 유형 중 32가지를 수집하여 평균(13가지 데이터 유형)을 크게 초과하며, 이전까지 1위를 차지했던 Google Gemini를 넘어섰습니다.
2010년대부터 주요 플랫폼들은 주의력의 수익화(타겟 광고, 추천 알고리즘)로 지배력을 구축해왔습니다. 생성 AI의 출현으로 새로운 패러다임이 나타납니다: 더 이상 주의를 끌지 않고, 사용자와 점점 더 개인화되고 맥락적인 공간에서 직접 상호작용합니다.
Meta는 Facebook/Instagram 생태계에 보조자를 통합함으로써 데이터 활용에서 새로운 경지에 도달했습니다. 사용자 동의는 복잡한 인터페이스와 불투명한 개인정보 보호 정책 속에서 점점 더 상징화되고 있습니다.
Meta AI, 데이터 수집의 최강자
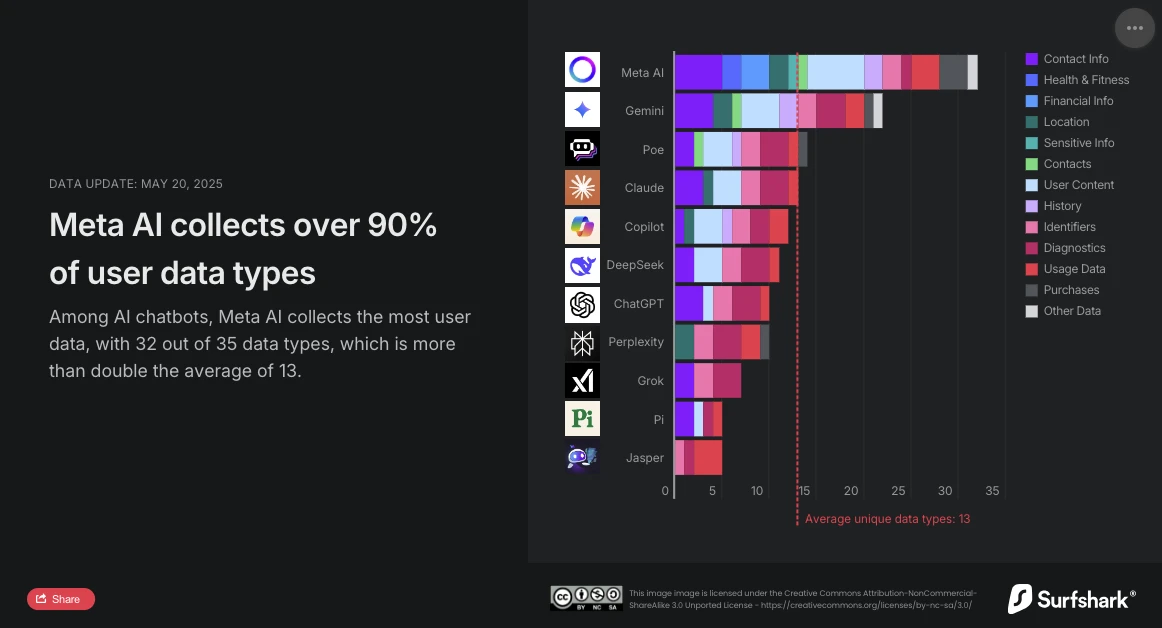
Surfshark의 연구는 AI 챗봇의 데이터 수집 규모를 강조합니다: 분석된 모든 애플리케이션이 사용자 데이터를 수집하고, 45%는 위치 데이터를 수집하며, 약 30%(Jasper, Poe, Copilot 등)는 광고 추적을 통해 다른 서비스의 데이터와 교차하거나 데이터 브로커에게 판매합니다.
데이터 브로커는 개인 데이터를 구매하고 판매하는 전문 기업입니다. 이들은 애플리케이션, 웹사이트, 공개 데이터베이스에서 정보를 수집하여 사용자의 상세한 프로필을 만들어 광고주, 보험사, 고용주, 때로는 공공기관에 판매합니다.
Acxiom, Experian, Epsilon 및 Oracle Data Cloud와 같은 대형 기업들이 이러한 정보를 활용하여 수십억 달러의 수익을 올리고 있습니다. 일부 지역에서는 규제가 강화되고 있지만, 시장은 여전히 전 세계적으로 거의 규제되지 않은 상태입니다.
연구에 따르면, Meta AI는 금융 정보, 건강 및 체력에 대한 데이터를 수집하는 유일한 애플리케이션입니다. 또한 인종 또는 민족 데이터, 성적 지향, 임신 또는 출산 정보, 장애, 종교적 또는 철학적 신념, 노조 가입, 정치적 의견, 유전 정보 또는 생체 데이터를 수집하는 유일한 애플리케이션입니다.
Surfshark의 프랑스 담당자 Maud Lepetit는 경고합니다:
"Meta는 Facebook, Instagram 또는 Audience Network를 통해 데이터를 수집하는 데 그치지 않습니다. 오늘날 그들은 같은 논리를 AI 보조자에 적용하여 공개 게시물, 사진, 메시지뿐만 아니라 인터페이스에 직접 입력된 데이터로 이를 강화하고 있습니다. 이는 생성 AI가 개인 데이터에 대한 안전장치 없이 작동할 때 발생할 수 있는 잠재적 일탈의 새로운 시연입니다."
Meta AI는 또한 Copilot과 함께 사용자의 신원과 관련된 데이터를 타겟 광고의 목적으로 제3자와 공유하는 유일한 애플리케이션입니다. 그러나 24가지 데이터 유형을 활용하여 Copilot(장치 ID 및 광고 데이터만 사용)과는 크게 차별화됩니다.
ChatGPT, 절제된 전략
OpenAI는 보다 신중한 접근 방식을 채택합니다. 수집하는 10가지 데이터 유형 중 사용자 연락처, 사용자 콘텐츠, 사용 및 진단 데이터가 있으며, ChatGPT는 광고 추적이나 상업적 목적으로 제3자와의 데이터 공유를 사용하지 않습니다. 또한 30일 후 삭제되는 "임시 채팅" 옵션은 서비스 연속성과 개인정보 보호 사이에서 흥미로운 절충안을 제공합니다. 사용자는 OpenAI에 모델 훈련을 위한 데이터 삭제를 요청할 수도 있습니다.
DeepSeek, 겉보기에는 조용하지만 실질적인 위험
중국 솔루션 DeepSeek은 11가지 데이터 유형을 수집하며 중간에 위치하지만, 데이터 저장 장소(중화인민공화국)와 The Hacker News가 보도한 중요한 보안 위반(백만 개 이상의 대화 기록 유출)으로 인해 서버 위치와 사이버 보안 관행이 수집된 데이터 수보다 더 중요하다는 사실을 상기시킵니다.
Meta, 이번 주부터 유럽 사용자 데이터 활용
Meta가 5월 27일부터 프랑스와 유럽에서 데이터 수집을 시작하여 AI 모델을 훈련할 예정인 가운데, Maud Lepetit는 상기시킵니다:
"인간과 달리 생성 AI는 책임을 지지 않습니다. 무엇이든 배울 수 있지만, 배우지 않은 것을 잊을 수 없습니다. 챗봇에 입력한 내용은 시스템에 영구적으로 남을 수 있습니다."
Meta의 개인 데이터 활용에 반대하는 경우, 마감일 전에 이를 수행해야 합니다. 사용자가 명시적으로 동의하지 않아도 되는 '옵트아웃' 원칙에 따라 이루어지는 Meta의 접근 방식은 GDPR과의 일치 여부에 대한 의문을 제기합니다. Meta가 사전 동의 없이 수집을 정당화하기 위해 제시한 정당한 이익은 NYOB 및 소비자 단체가 회사에 대한 조치를 계속하게 했습니다. CNIL은 AI 시스템 훈련을 위한 법적 근거로서의 정당한 이익 사용이 자체적으로 불법은 아니지만, 관련된 사람들의 기본적인 권리와 이익을 주의 깊게 평가해야 한다고 보고 있습니다.
더 잘 이해하기
GDPR이란 무엇이며 Meta AI의 데이터 수집 관행에 어떻게 적용되나요?
GDPR(일반 데이터 보호 규정)은 개인의 개인 데이터를 보호하기 위한 EU 규정입니다. 데이터 수집 및 사용을 위해 명시적인 동의('옵트인')가 필요합니다. '옵트아웃' 동의를 사용하는 Meta AI의 경우, GDPR 준수에 대한 논란이 있으며, 이는 법적 조치로 이어졌습니다.
개인 데이터 규제에서 '정당한 이익' 개념은 어떻게 사용되나요?
정당한 이익은 명시적 동의 없이 데이터를 처리하는 GDPR의 법적 근거입니다. 기업이 정당한 이익이 개인의 기본 권리를 능가하지 않는다는 것을 보여야 합니다. 이는 주관적일 수 있는 균형 잡힌 평가에 의존하기 때문에 논란의 여지가 있는 근거입니다.