작년 12월, AI2는 완전한 오픈 소스 모델 가족 OLMO 2를 발표한 후, Allen Institute for Artificial Intelligence (AI2)는 오픈 소스에 대한 노력을 계속하고 있습니다. 이번에 AI2는 Llama 3.1을 기반으로 하고, 검증 가능한 보상에 의한 강화 학습(RLVR) 프레임워크를 활용한 Tülu 3 405B를 출시했습니다. 이 새로운 모델은 DeepSeek V3 (이를 기반으로 한 DeepSeek R1) 및 GPT-4o와 같은 모델들과 경쟁하거나 더 나은 성능을 보여줍니다. 또한 Llama 3.1 405B Instruct 및 Nous Research의 Hermes 3 405B와 같은 이전 후속 교육 모델을 능가합니다.
최적화된 후속 교육
Tülu 3 405B의 후속 교육 방식은 AI2가 작년 11월에 발표한 Tülu 3 8B 및 70B와 유사합니다. 이는 데이터의 세심한 선별, 감독된 미세 조정(SFT), 직접 선호 최적화(DPO) 및 검증 가능한 보상에 의한 강화 학습(RLVR)을 포함합니다.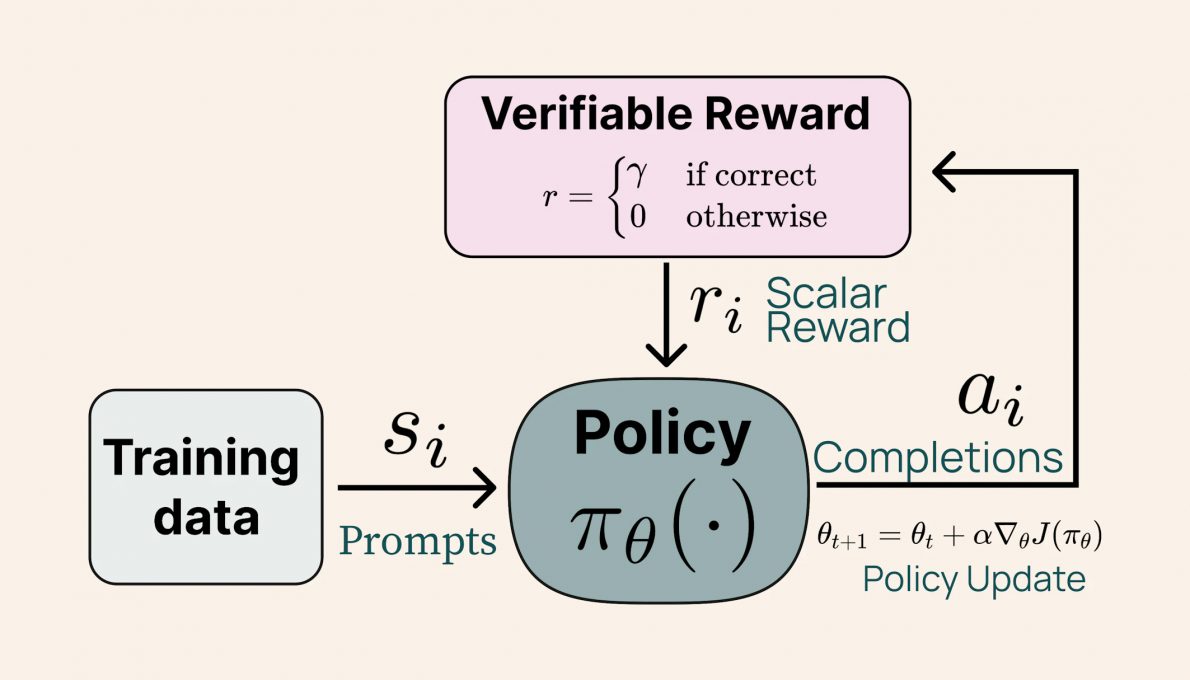 AI 제공 이미지. 검증 가능한 보상에 의한 강화 학습(RLVR) 프로세스를 설명하는 다이어그램. 이 새로운 방법은 수학 문제 해결 및 지침 추적과 같은 복잡한 작업에서 Tülu 모델의 성능을 크게 향상시킵니다. 흥미롭게도, 결과는 모델의 규모가 RLVR의 효율성에 긍정적인 영향을 미친다는 것을 보여줍니다. 더 작은 모델은 다양한 데이터 세트에서 훈련을 받는 반면, Tülu 3 405B는 더욱 전문화된 데이터에 집중하여 더 나은 성능을 발휘합니다.
AI 제공 이미지. 검증 가능한 보상에 의한 강화 학습(RLVR) 프로세스를 설명하는 다이어그램. 이 새로운 방법은 수학 문제 해결 및 지침 추적과 같은 복잡한 작업에서 Tülu 모델의 성능을 크게 향상시킵니다. 흥미롭게도, 결과는 모델의 규모가 RLVR의 효율성에 긍정적인 영향을 미친다는 것을 보여줍니다. 더 작은 모델은 다양한 데이터 세트에서 훈련을 받는 반면, Tülu 3 405B는 더욱 전문화된 데이터에 집중하여 더 나은 성능을 발휘합니다. 모델 성능
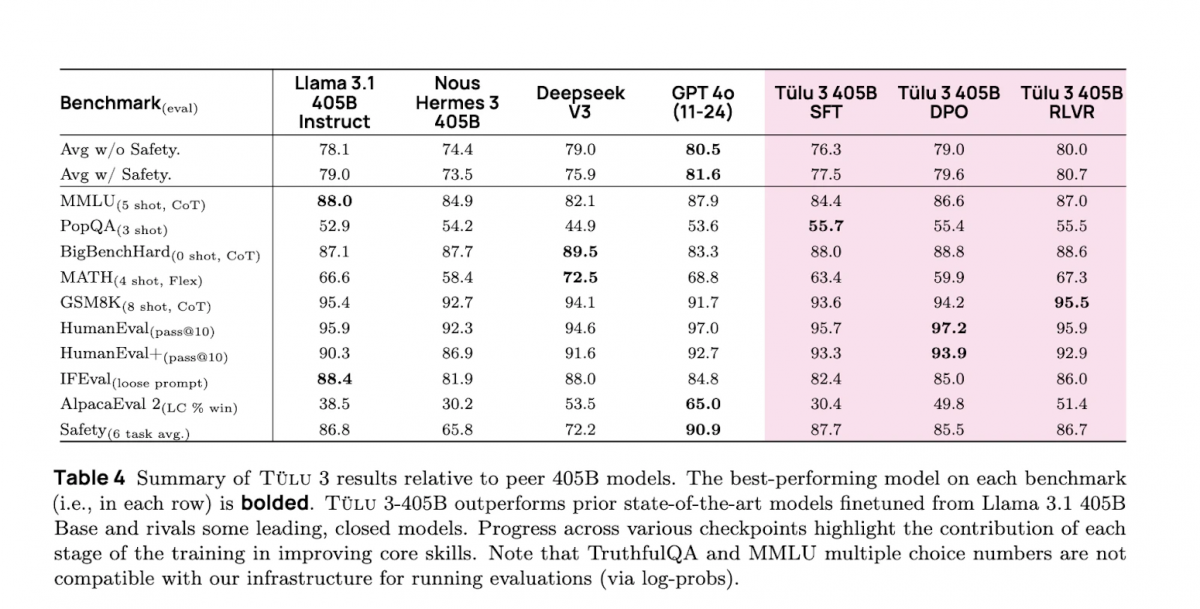
AI2의 내부 평가에 따르면, Tülu 3 405B는 14,000개의 질문-답변 쌍으로 모델의 정보 회수 및 생성 능력을 검증하는 PopQA 벤치마크에서 DeepSeek V3, GPT-4o 및 Llama 3.1 405B를 능가했습니다. 이 모델은 또한 OpenAI가 만든 약 8,500개의 학업 수준 수학 문제로 구성된 GSM8K에서 해당 범주에 속한 모든 모델 중에서 가장 높은 성능을 기록했습니다. 이는 다단계 수학적 추론을 수행하는 언어 모델의 능력을 테스트하기 위한 것입니다.