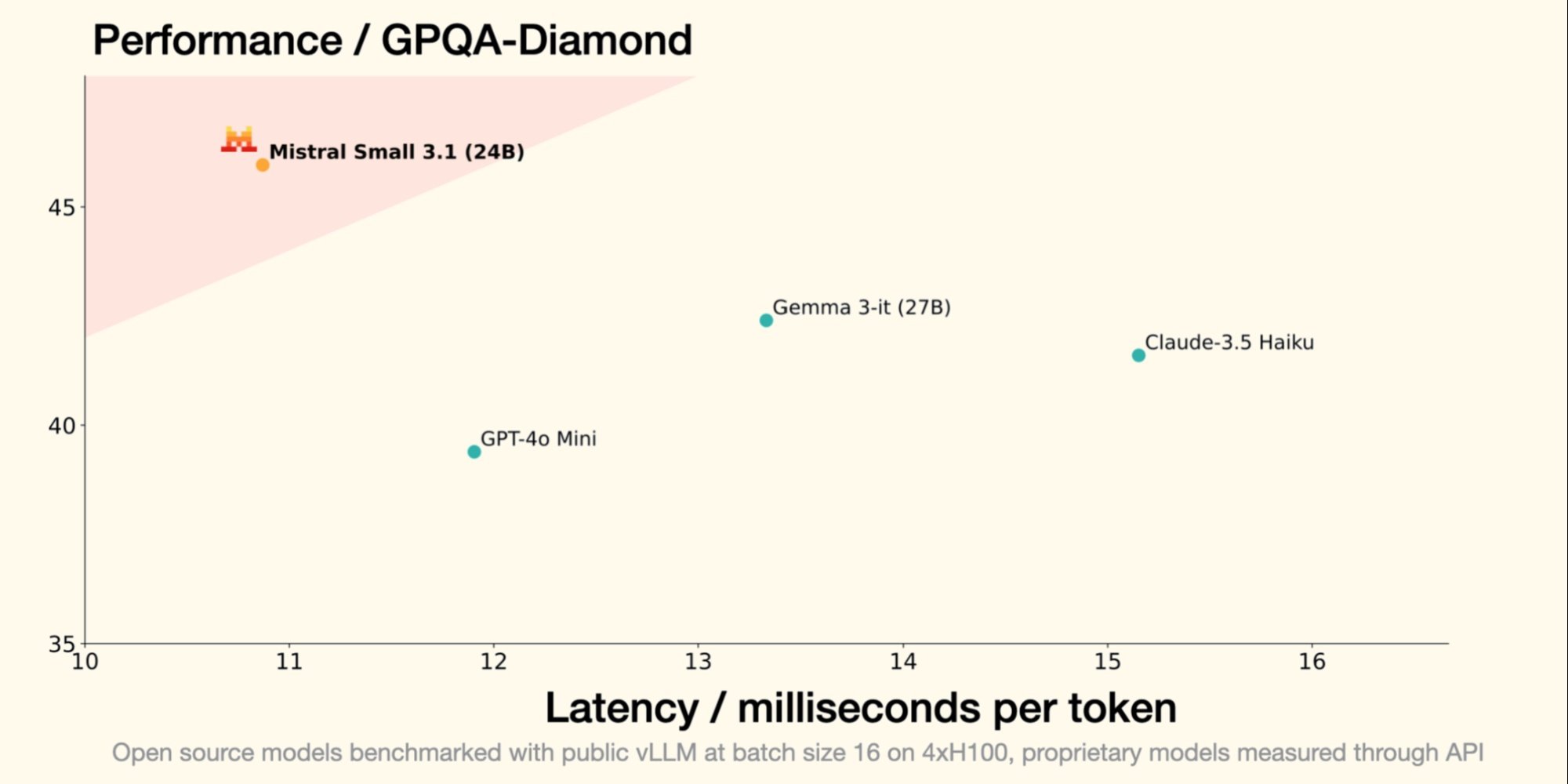
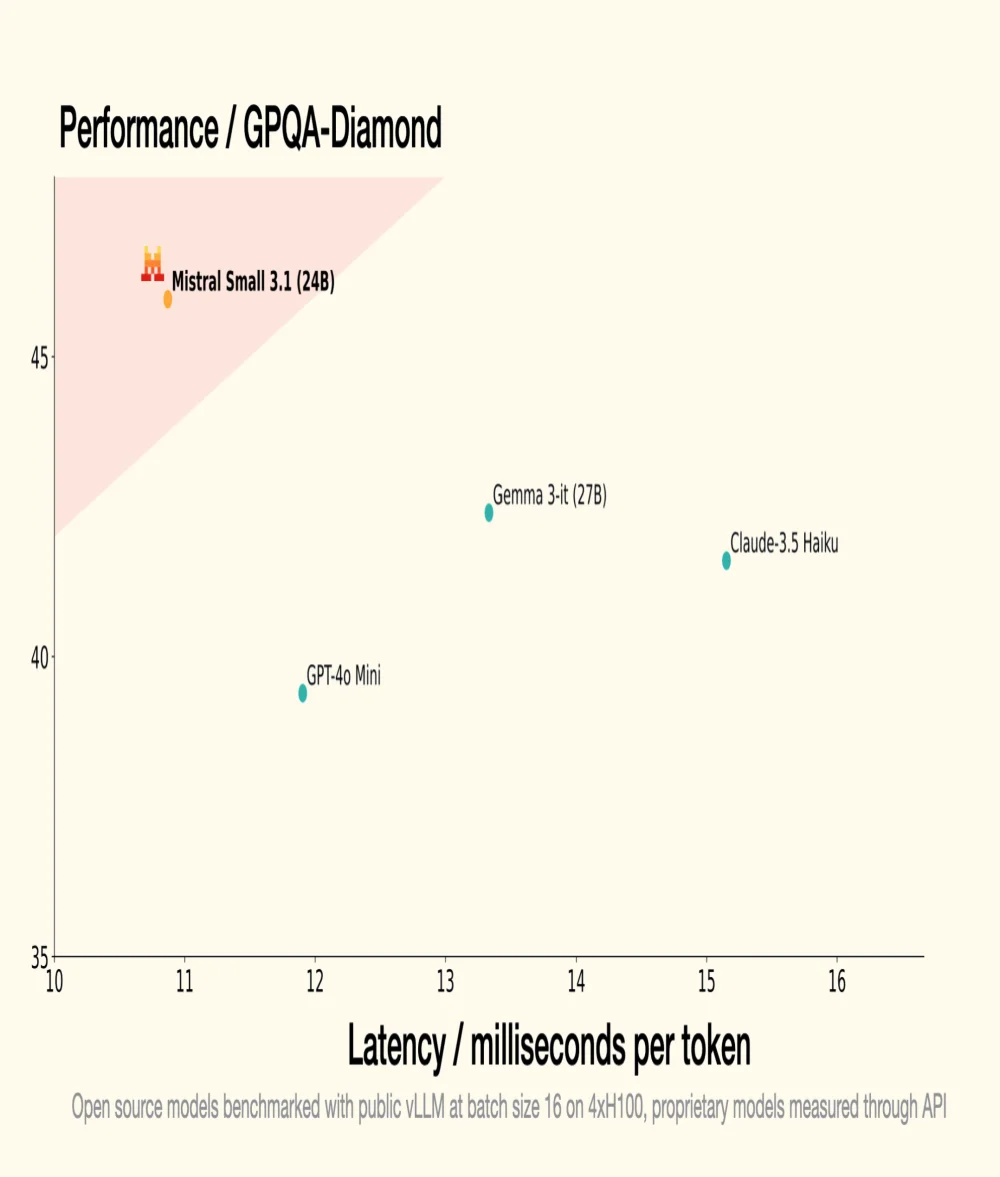
Lo scorso 30 gennaio, Mistral AI, unicorno francese della GenAI, ha introdotto Small 3, un LLM con 24 miliardi di parametri, dimostrando che per essere performante, un LLM non necessita di un numero astronomico di parametri. Small 3.1, il suo successore, mantiene un'architettura compatta introducendo miglioramenti significativi in termini di prestazioni, comprensione multimodale e gestione di contesti lunghi, superando così modelli come Gemma 3-it 27B di Google e GPT-4o Mini di OpenAI.
Fonte: Mistral AI
Ottimizzazione delle prestazioni
- Una versione istruita, Mistral Small 3.1 Instruct, pronta per essere utilizzata per compiti conversazionali e di comprensione del linguaggio;
- Una versione pre-allenata, Mistral Small 3.1 Base, ideale per il fine-tuning e la specializzazione su ambiti specifici (sanità, finanza, giuridico, ecc.).
- Small 3.1 Instruct mostra prestazioni migliori rispetto a Gemma 3-it (27B) di Google in compiti testuali, multimodali e multilingue;
- Supera GPT-4o Mini di OpenAI in benchmark come MMLU, HumanEval e LongBench v2, grazie alla sua finestra contestuale estesa a 128.000 token;
- Supera anche Claude-3.5 Haiku in compiti complessi che coinvolgono contesti lunghi e dati multimodali;
- Eccelle rispetto a Cohere Aya-Vision (32B) in benchmark multimodali come ChartQA e DocVQA, dimostrando una comprensione avanzata dei dati visivi e testuali;
- Small 3.1 mostra alte prestazioni nel multilinguismo, superando i suoi concorrenti in categorie come le lingue europee e asiatiche.
Per capire meglio
Che cos'è un LLM (Large Language Model) in termini di tecnologia e funzionamento?
Un LLM è un modello di intelligenza artificiale progettato per comprendere e generare linguaggio naturale. È composto da miliardi di parametri regolati attraverso l'apprendimento su grandi quantità di testo per prevedere la parola successiva in una frase. I LLM sono utilizzati per applicazioni come la traduzione automatica, il riassunto di testi e gli agenti conversazionali.
Che cos'è la licenza Apache 2.0 e perché è importante per i progetti open source?
La licenza Apache 2.0 è una licenza software open source che consente agli utenti di apportare modifiche significative e utilizzare il software per scopi commerciali o privati concedendo brevetti. È importante perché garantisce che i contributi rimangano liberi e accessibili, stimolando l'innovazione e l'adozione di nuove tecnologie.