
TLDR : L'assistente conversazionale Meta AI è il più intrusivo in materia di raccolta di dati personali, superando Google Gemini, secondo uno studio di Surfshark. Meta AI raccoglie 32 tipi di dati su 35 analizzati, inclusi dati sensibili come orientamento sessuale, credenze religiose e dati biometrici, mentre altre applicazioni come ChatGPT di OpenAI adottano un approccio più prudente.
Sommario
Surfshark, specialista in cybersicurezza, ha recentemente pubblicato un aggiornamento del suo studio comparativo sulla raccolta di dati personali da parte dei principali chatbot sul mercato. L'analisi è inequivocabile: Meta AI è l'assistente conversazionale più invasivo. Con 32 tipi di dati raccolti sui 35 analizzati, supera di gran lunga la media (13 tipi di dati) e ora precede Google Gemini, che fino ad allora occupava il primo posto.
Dagli anni 2010, le grandi piattaforme hanno costruito la loro dominazione sulla monetizzazione dell'attenzione (pubblicità mirata, algoritmi di raccomandazione). Con l'avvento dell'IA generativa, si delinea un nuovo paradigma: non più catturare l'attenzione, ma interagire direttamente con l'utente in spazi sempre più personalizzati e contestuali.
Meta, integrando il suo assistente nell'ecosistema Facebook/Instagram, supera una soglia nell'utilizzo dei dati. Il consenso dell'utente, spesso diluito in interfacce complesse e politiche di riservatezza opache, sembra sempre più simbolico.
Meta AI, il più avido di dati
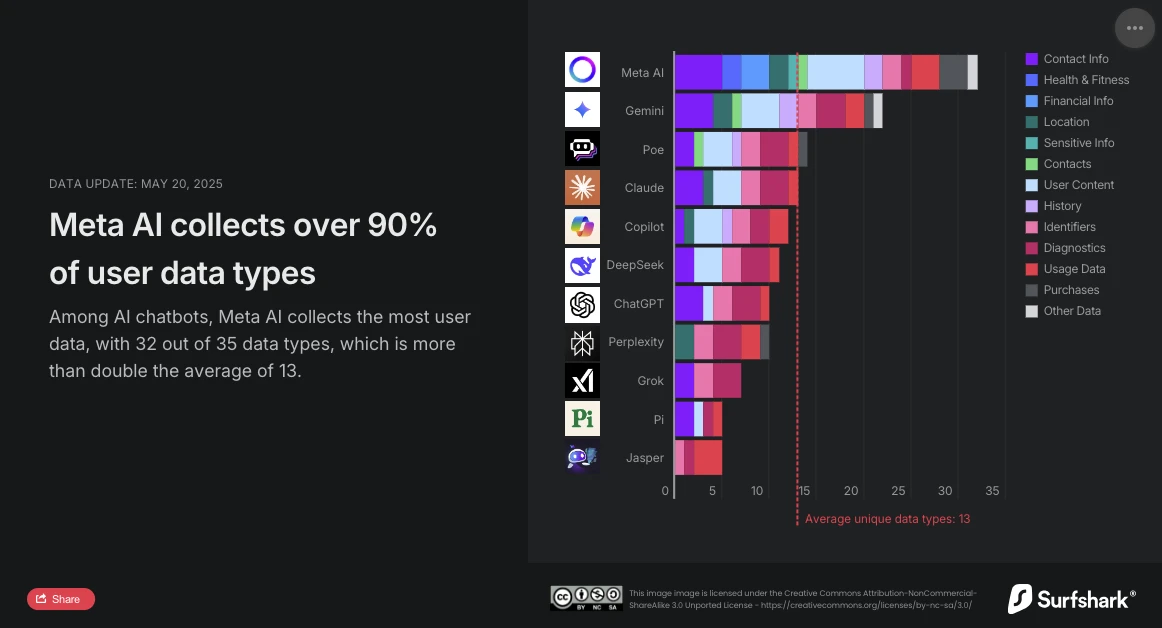
Lo studio di Surfshark mette in evidenza l'ampiezza della raccolta di dati da parte dei chatbot IA: tutte le applicazioni analizzate raccolgono dati utente, il 45% raccoglie la geolocalizzazione, e quasi il 30% (tra cui Jasper, Poe e Copilot) pratica il tracking pubblicitario, cioè incrociano i dati con quelli di altri servizi o li rivendono a data broker.
I data broker sono aziende specializzate nell'acquisto e nella vendita di dati personali. Compilano informazioni provenienti da applicazioni, siti web e banche dati pubbliche per creare profili dettagliati degli utenti, rivenduti poi ad inserzionisti, assicuratori, datori di lavoro, e talvolta anche a enti pubblici.
Tra le maggiori società del settore, troviamo Acxiom, Experian, Epsilon e Oracle Data Cloud, che movimentano miliardi di dollari sfruttando queste informazioni. Nonostante una regolamentazione crescente in alcune regioni, il mercato rimane poco regolamentato a livello mondiale.
Secondo lo studio, Meta AI è l'unico a raccogliere dati su informazioni finanziarie, salute e forma fisica. L'applicazione non si ferma qui: è anche l'unica a raccogliere informazioni particolarmente sensibili: dati razziali o etnici, orientamento sessuale, informazioni sulla gravidanza o il parto, disabilità, credenze religiose o filosofiche, appartenenza sindacale, opinioni politiche, informazioni genetiche o dati biometrici.
Maud Lepetit, responsabile Francia presso Surfshark, avverte:
"Meta non si limita ad aspirare i dati tramite Facebook, Instagram o il suo Audience Network. Oggi, applicano la stessa logica al loro assistente IA, alimentandolo con pubblicazioni pubbliche, foto, messaggi... ma anche con i dati inseriti direttamente nell'interfaccia. È una nuova dimostrazione delle derive possibili quando l'IA generativa si basa su dati personali senza cautele".
Meta AI è anche l'unico con Copilot a raccogliere dati legati all'identità dell'utente per condividerli con terzi nell'ambito della pubblicità mirata. Tuttavia, con 24 tipi di dati sfruttati, si distingue nettamente da Copilot, che ne utilizza solo due (ID dispositivo e dati pubblicitari).
ChatGPT, una strategia di moderazione
OpenAI adotta un approccio più prudente. Con solo 10 tipi di dati raccolti, tra cui le coordinate, il contenuto dell'utente, i dati di utilizzo e diagnostica, ChatGPT non ricorre né al tracking pubblicitario né alla condivisione con terzi a fini commerciali. Inoltre, l'opzione delle "chat temporanee", eliminate dopo 30 giorni, offre un compromesso interessante tra continuità del servizio e rispetto della privacy. I suoi utenti possono anche richiedere a OpenAI la cancellazione dei loro dati per l'addestramento dei suoi modelli.
DeepSeek, tra discrezione apparente e rischi concreti
La soluzione cinese DeepSeek si posiziona a metà strada con 11 tipi di dati raccolti, tra cui la cronologia delle chat. Tuttavia, il luogo di archiviazione dei dati (la Repubblica Popolare Cinese) e una violazione della sicurezza significativa riportata da The Hacker News (fuga di oltre un milione di registrazioni di conversazioni) ricordano che la localizzazione dei server e le pratiche di cybersicurezza pesano tanto quanto il numero di dati raccolti.
I dati degli utenti europei sfruttati da Meta già da questa settimana
Mentre Meta inizierà la raccolta di dati in Francia e in Europa già dal 27 maggio per addestrare i suoi modelli di IA, Maud Lepetit ricorda:
"A differenza di un umano, l'IA generativa non rende conto. Può imparare qualsiasi cosa, ma non può disimparare. Ciò che si inserisce in un chatbot rimane nel suo sistema, potenzialmente per sempre".
Se vi opponete all'uso dei vostri dati personali da parte di Meta, dovete farlo prima di questa scadenza. Il suo approccio, che si basa sul principio dell'"opt-out", dove l'utente deve esprimere il suo rifiuto, piuttosto che su un consenso esplicito ("opt-in"), solleva questioni sulla sua conformità con il GDPR. L'interesse legittimo invocato da Meta per giustificare questa raccolta senza previo consenso, ha portato NYOB e associazioni di consumatori a continuare le loro azioni contro l'azienda. la CNIL, dal canto suo, ritiene che il ricorso all'interesse legittimo come base legale per addestrare un sistema di IA non sia illegale di per sé, ma richiede una valutazione attenta degli interessi e dei diritti fondamentali delle persone coinvolte.
Per capire meglio
Cos'è il GDPR e come si applica alle pratiche di raccolta dati di Meta AI?
Il GDPR (Regolamento Generale sulla Protezione dei Dati) è una normativa dell'UE volta a proteggere i dati personali degli individui. Richiede un consenso esplicito ('opt-in') per la raccolta e l'uso dei dati. Nel caso di Meta AI, che utilizza il consenso per 'opt-out', ci sono dibattiti sulla conformità al GDPR, che hanno portato ad azioni legali.
Come viene utilizzato il concetto di 'interesse legittimo' nella regolamentazione dei dati personali?
L'interesse legittimo è una base legale nel GDPR per elaborare i dati senza consenso esplicito. Richiede che le aziende dimostrino che i loro interessi legittimi non prevalgono sui diritti fondamentali degli individui. È una base controversa poiché la sua applicazione dipende da una valutazione equilibrata che può essere soggettiva.