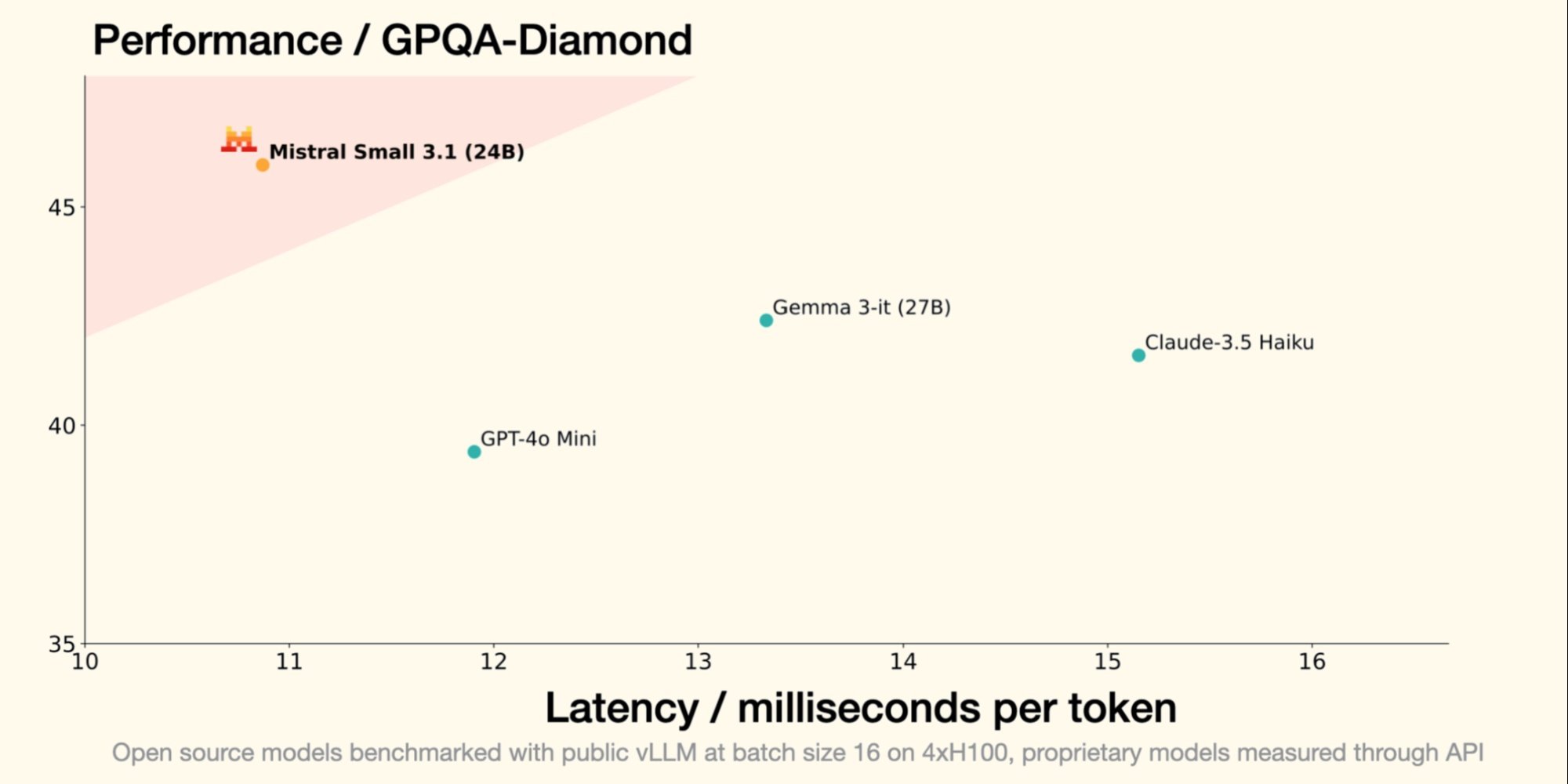
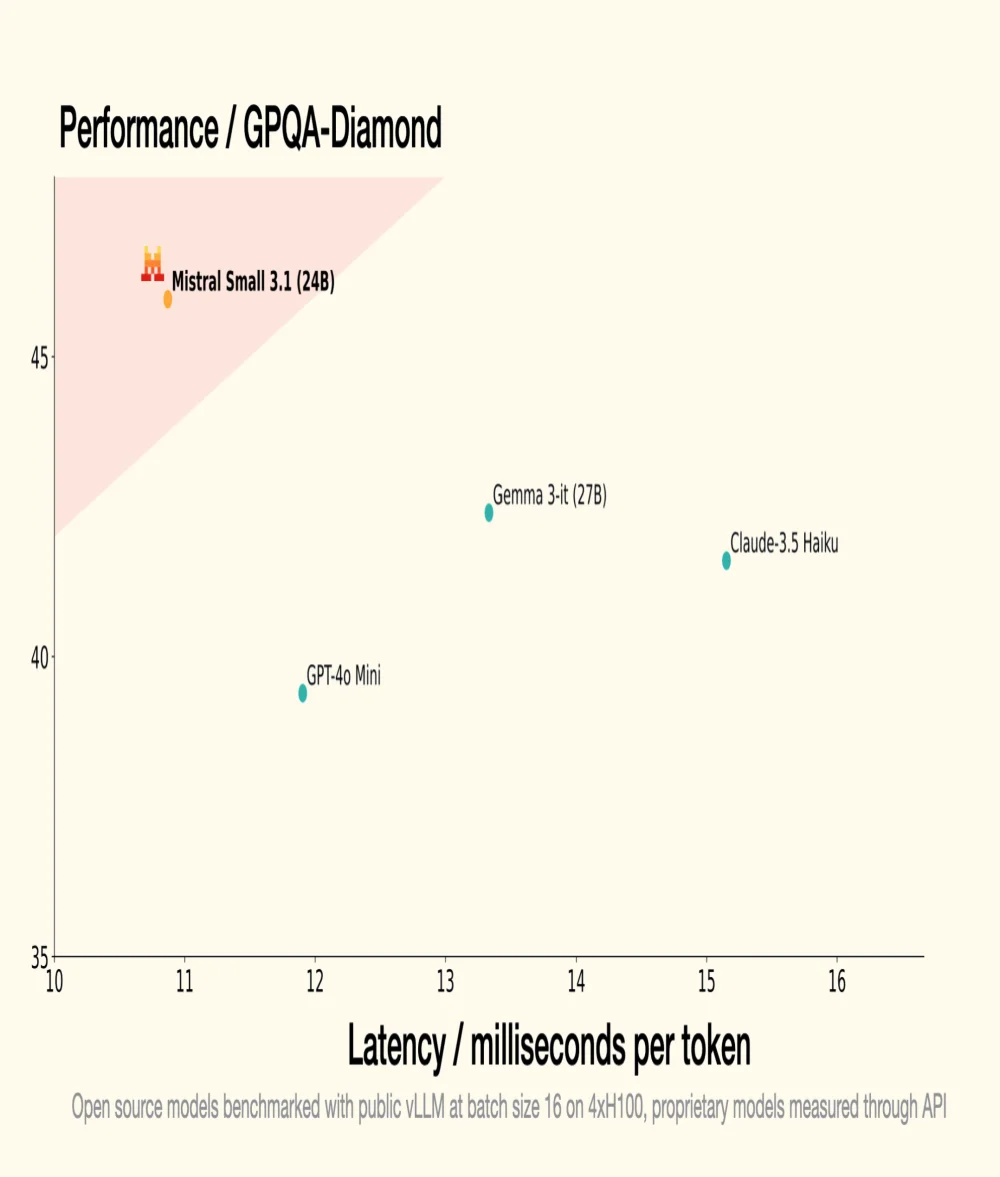
El pasado 30 de enero, Mistral AI, unicornio francés de la GenAI, introdujo Small 3, un LLM de 24 mil millones de parámetros, demostrando que para ser eficiente, un LLM no requiere un número astronómico de parámetros. Small 3.1, su sucesor, mantiene una arquitectura compacta mientras introduce mejoras significativas en términos de rendimiento, comprensión multimodal y gestión de contextos largos, superando así modelos como Gemma 3-it 27B de Google y GPT-4o Mini de OpenAI.
Fuente: Mistral AI
Optimización del rendimiento
- Una versión instruida, Mistral Small 3.1 Instruct, lista para ser utilizada en tareas conversacionales y de comprensión del lenguaje;
- Una versión preentrenada, Mistral Small 3.1 Base, ideal para el fine-tuning y la especialización en dominios específicos (salud, finanzas, jurídico, etc.).
- Small 3.1 Instruct muestra un mejor rendimiento que Gemma 3-it (27B) de Google en tareas textuales, multimodales y multilingües;
- Supera a GPT-4o Mini de OpenAI en benchmarks como MMLU, HumanEval y LongBench v2, especialmente gracias a su ventana contextual extendida a 128,000 tokens;
- También supera a Claude-3.5 Haiku en tareas complejas que implican contextos largos y datos multimodales;
- Se destaca frente a Cohere Aya-Vision (32B) en benchmarks multimodales como ChartQA y DocVQA, demostrando una comprensión avanzada de los datos visuales y textuales;
- Small 3.1 muestra un alto rendimiento en multilingüismo, superando a sus competidores en categorías como idiomas europeos y asiáticos.
Para entender mejor
¿Qué es un LLM (Large Language Model) en términos de tecnología y funcionamiento?
Un LLM es un modelo de inteligencia artificial diseñado para comprender y generar lenguaje natural. Está compuesto por miles de millones de parámetros ajustados mediante entrenamiento con grandes cantidades de texto para predecir la siguiente palabra en una oración. Los LLM se utilizan para aplicaciones como la traducción automática, el resumen de textos y los agentes conversacionales.
¿Qué es la licencia Apache 2.0 y por qué es importante para los proyectos de código abierto?
La licencia Apache 2.0 es una licencia de software de código abierto que permite a los usuarios realizar modificaciones significativas y usar el software con fines comerciales o privados mientras otorgan patentes. Es importante porque asegura que las contribuciones sigan siendo libres y accesibles, fomentando la innovación y la adopción de nuevas tecnologías.