
TLDR : El asistente conversacional Meta AI es el más intrusivo en cuanto a la recopilación de datos personales, superando a Google Gemini, según un estudio de Surfshark. Meta AI recopila 32 tipos de datos de los 35 analizados, incluidas informaciones sensibles como orientación sexual, creencias religiosas y datos biométricos, mientras que otras aplicaciones como ChatGPT de OpenAI adoptan un enfoque más cauteloso.
Índice
Surfshark, especialista en ciberseguridad, ha publicado recientemente una actualización de su estudio comparativo sobre la recopilación de datos personales por los principales chatbots del mercado. El análisis es concluyente: Meta AI es el asistente conversacional más intrusivo. Con 32 tipos de datos recopilados de los 35 analizados, supera ampliamente el promedio (13 tipos de datos) y ahora adelanta a Google Gemini, que ocupaba hasta entonces el primer lugar.
Desde la década de 2010, las grandes plataformas han construido su dominio sobre la monetización de la atención (publicidad dirigida, algoritmos de recomendación). Con el advenimiento de la IA generativa, se dibuja un nuevo paradigma: ya no captar la atención, sino interactuar directamente con el usuario en espacios cada vez más personalizados y contextuales.
Meta, al integrar su asistente en el ecosistema Facebook/Instagram, cruza un umbral en la explotación de datos. El consentimiento del usuario, a menudo diluido en interfaces complejas y políticas de privacidad opacas, parece cada vez más simbólico.
Meta AI, el más voraz en datos
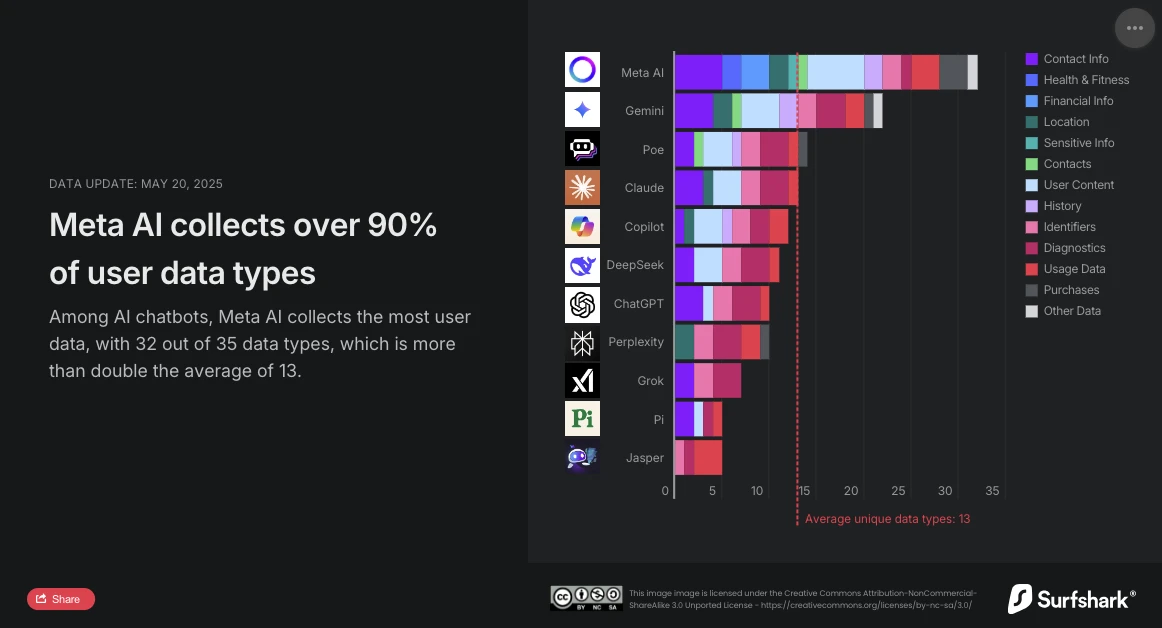
El estudio de Surfshark pone en evidencia la magnitud de la recopilación de datos por los chatbots IA: todas las aplicaciones analizadas recopilan datos de usuario, el 45% recoge la geolocalización, y cerca del 30%, (notablemente Jasper, Poe y Copilot) practican el seguimiento publicitario, es decir, cruzan los datos con los de otros servicios o los venden a data brokers.
Los data brokers son empresas especializadas en la compra y venta de datos personales. Compilan información de aplicaciones, sitios web y bases de datos públicas para crear perfiles detallados de los usuarios, que luego venden a anunciantes, aseguradoras, empleadores, y a veces incluso a organismos públicos.
Entre las mayores empresas del sector, se encuentran Acxiom, Experian, Epsilon y Oracle Data Cloud, que manejan miles de millones de dólares explotando esta información. A pesar de una regulación creciente en algunas regiones, el mercado sigue poco regulado a escala mundial.
Según el estudio, Meta AI es el único en recopilar datos sobre información financiera, salud y estado físico. La aplicación no se detiene ahí: también es la única en recopilar información particularmente sensible: datos raciales o étnicos, orientación sexual, información sobre embarazo o parto, discapacidad, creencias religiosas o filosóficas, pertenencia sindical, opiniones políticas, información genética o datos biométricos.
Maud Lepetit, responsable de Francia en Surfshark, alerta:
"Meta no se contenta con absorber datos a través de Facebook, Instagram o su Audience Network. Hoy, aplican la misma lógica a su asistente IA, alimentándolo con publicaciones públicas, fotos, mensajes... pero también con los datos ingresados directamente en la interfaz. Es una nueva demostración de los posibles desvíos cuando la IA generativa se basa en datos personales sin salvaguardias".
Meta AI es también el único junto con Copilot en recopilar datos relacionados con la identidad del usuario para compartirlos con terceros en el marco de la publicidad dirigida. Sin embargo, con 24 tipos de datos utilizados, se distingue claramente de Copilot, que solo utiliza dos (ID de dispositivo y datos publicitarios).
ChatGPT, una estrategia de moderación
OpenAI adopta un enfoque más prudente. Con solo 10 tipos de datos recopilados, entre los cuales se encuentran las coordenadas, el contenido del usuario, los datos de uso y diagnóstico, ChatGPT no recurre al seguimiento publicitario ni al intercambio con terceros con fines comerciales. Además, la opción de "chats temporales", eliminados después de 30 días, ofrece un compromiso interesante entre la continuidad del servicio y el respeto a la privacidad. Sus usuarios también pueden solicitar a OpenAI la eliminación de sus datos para el entrenamiento de sus modelos
DeepSeek, entre discreción aparente y riesgos concretos
La solución china DeepSeek se posiciona a medio camino con 11 tipos de datos recopilados, incluido el historial de chats. Sin embargo, el lugar de almacenamiento de los datos (la República Popular China) y una violación de seguridad importante reportada por The Hacker News (fuga de más de un millón de registros de conversaciones) recuerdan que la localización de los servidores y las prácticas de ciberseguridad pesan tanto como la cantidad de datos recopilados.
Los datos de los usuarios europeos explotados por Meta desde esta semana
Mientras que Meta va a comenzar su recopilación de datos en Francia y en Europa desde este 27 de mayo para entrenar sus modelos de IA, Maud Lepetit recuerda:
"A diferencia de un humano, la IA generativa no rinde cuentas. Puede aprender cualquier cosa, pero no puede desaprender. Lo que ingresas en un chatbot permanece en su sistema, potencialmente para siempre".
Si te opones a la explotación de tus datos personales por Meta, debes hacerlo antes de esta fecha límite. Su enfoque, que se basa en el principio de "opt-out", donde el usuario debe expresar su rechazo, en lugar de un consentimiento explícito ("opt-in"), plantea preguntas sobre su cumplimiento con el RGPD. El interés legítimo invocado por Meta para justificar esta recopilación sin consentimiento previo, ha llevado a NYOB y asociaciones de consumidores a continuar sus acciones contra la empresa. La CNIL, por su parte, estima que el uso del interés legítimo como base legal para entrenar un sistema de IA no es ilegal en sí mismo, pero requiere una evaluación atenta de los intereses y derechos fundamentales de las personas afectadas.
Para entender mejor
¿Qué es el RGPD y cómo se aplica a las prácticas de recopilación de datos de Meta AI?
El RGPD (Reglamento General de Protección de Datos) es una normativa de la UE que protege los datos personales de los individuos. Exige consentimiento explícito ('opt-in') para la recopilación y uso de datos. En el caso de Meta AI, que utiliza consentimiento por 'opt-out', hay debates sobre la conformidad con el RGPD, lo que ha llevado a acciones legales.
¿Cómo se utiliza el concepto de 'interés legítimo' en la regulación de datos personales?
El interés legítimo es una base legal bajo el RGPD para procesar datos sin consentimiento explícito. Requiere que las empresas demuestren que sus intereses legítimos no prevalecen sobre los derechos fundamentales de las personas. Es una base controvertida ya que su aplicación depende de una evaluación equilibrada que puede ser subjetiva.