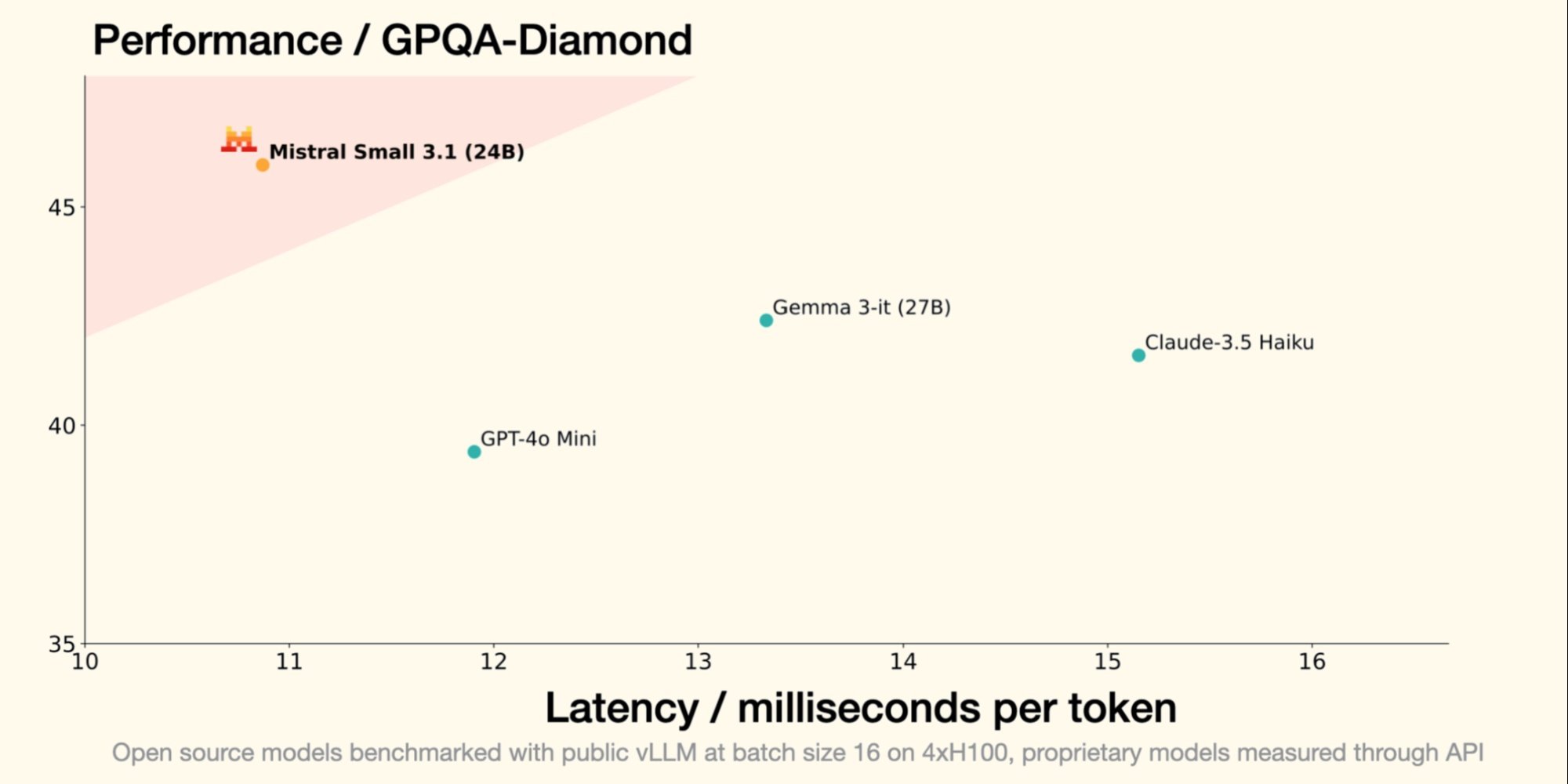
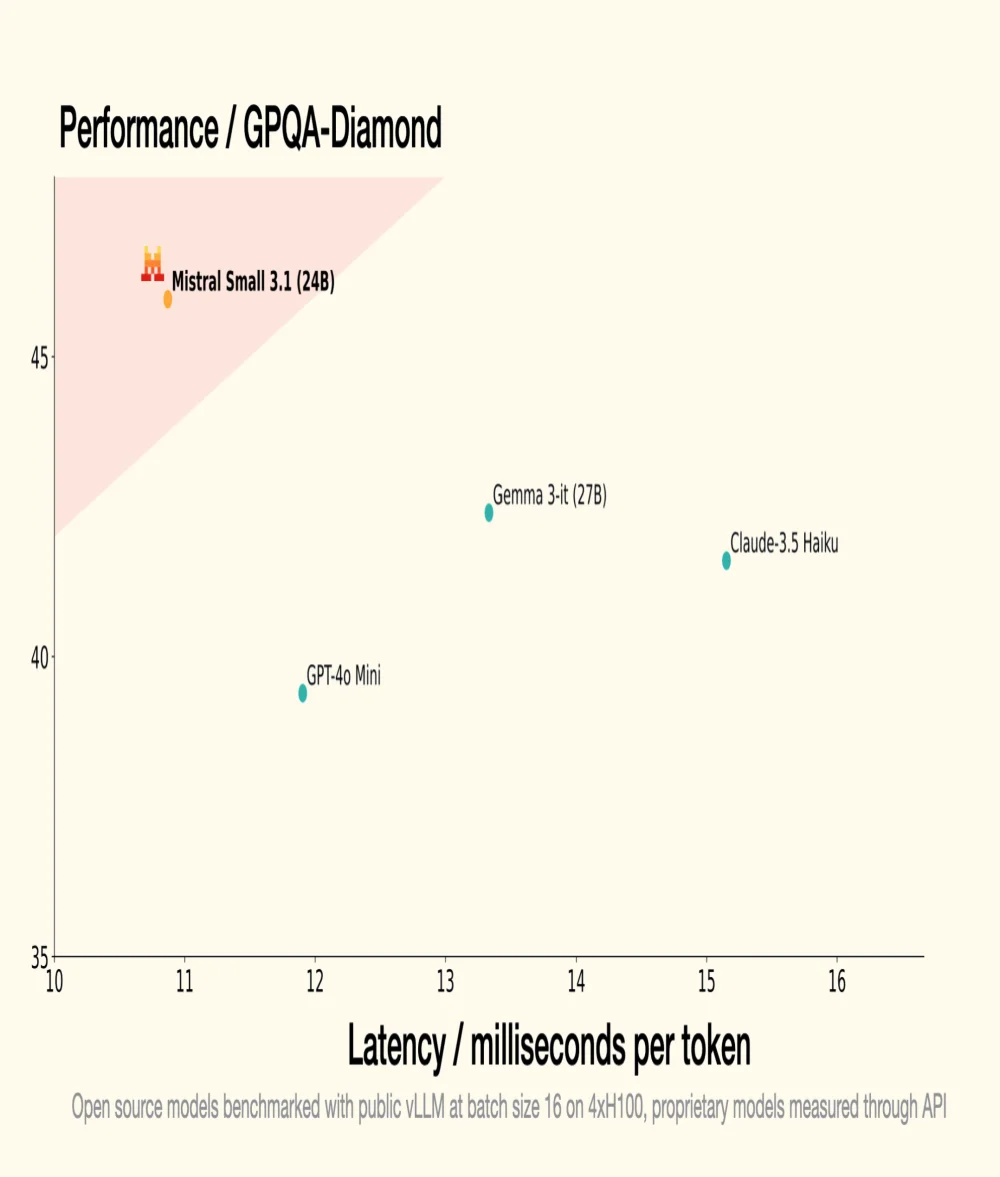
On January 30th, Mistral AI, the French GenAI unicorn, introduced Small 3, a 24 billion parameter LLM, demonstrating that to be effective, an LLM does not require an astronomical number of parameters. Small 3.1, its successor, maintains a compact architecture while introducing significant improvements in performance, multimodal understanding, and long context management, thus surpassing models like Google's Gemma 3-it 27B and OpenAI's GPT-4o Mini.
Source: Mistral AI
Performance Optimization
- An instructed version, Mistral Small 3.1 Instruct, ready to be used for conversational tasks and language understanding;
- A pre-trained version, Mistral Small 3.1 Base, ideal for fine-tuning and specialization in specific domains (health, finance, legal, etc.).
- Small 3.1 Instruct shows better performance than Google's Gemma 3-it (27B) in textual, multimodal, and multilingual tasks;
- It surpasses OpenAI's GPT-4o Mini on benchmarks like MMLU, HumanEval, and LongBench v2, notably thanks to its extended contextual window of 128,000 tokens;
- It also outperforms Claude-3.5 Haiku in complex tasks involving long contexts and multimodal data;
- It excels against Cohere Aya-Vision (32B) in multimodal benchmarks such as ChartQA and DocVQA, demonstrating advanced understanding of visual and textual data;
- Small 3.1 shows high performance in multilingualism, surpassing its competitors in categories such as European and Asian languages.
To better understand
What is a LLM (Large Language Model) in terms of technology and functioning?
A LLM is an artificial intelligence model designed to understand and generate natural language. It consists of billions of parameters adjusted through training on large amounts of text to predict the next word in a sentence. LLMs are used for applications like automatic translation, text summarization, and conversational agents.
What is the Apache 2.0 license and why is it significant for open source projects?
The Apache 2.0 license is an open-source software license that allows users to make significant modifications and use the software for commercial or private purposes while granting patents. It is significant because it ensures contributions remain free and accessible, fostering innovation and the adoption of new technologies.