
TLDR : The Meta AI conversational assistant is the most intrusive in personal data collection, surpassing Google Gemini, according to a study by Surfshark. Meta AI collects 32 types of data out of 35 analyzed, including sensitive information such as sexual orientation, religious beliefs, and biometric data, whereas other applications like OpenAI's ChatGPT take a more cautious approach.
Table of contents
Surfshark, a cybersecurity specialist, recently released an update to its comparative study on the collection of personal data by the leading chatbots on the market. The analysis is clear: Meta AI is the most intrusive conversational assistant. With 32 types of data collected out of the 35 analyzed, it far exceeds the average (13 types of data) and now surpasses Google Gemini, which previously held the top spot.
Since the 2010s, major platforms have built their dominance on monetizing attention (targeted advertising, recommendation algorithms). With the advent of generative AI, a new paradigm is emerging: not just capturing attention, but directly interacting with users in increasingly personalized and contextual spaces.
Meta, by integrating its assistant into the Facebook/Instagram ecosystem, crosses a threshold in data exploitation. User consent, often diluted in complex interfaces and opaque privacy policies, seems increasingly symbolic.
Meta AI, the Most Data-Hungry
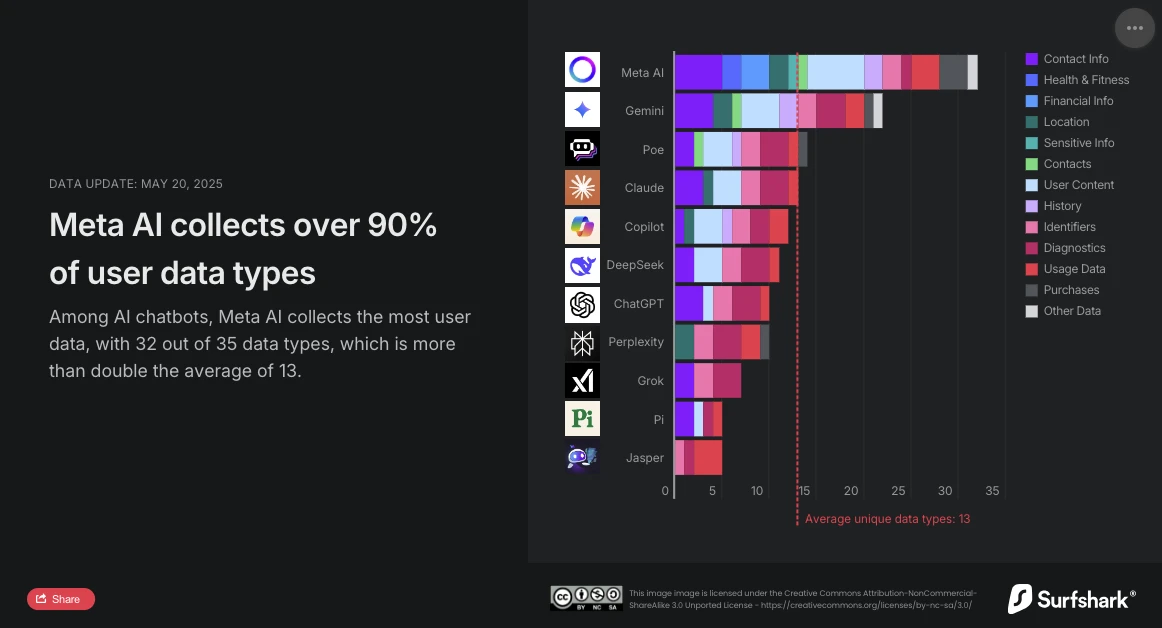
Surfshark's study highlights the extent of data collection by AI chatbots: all analyzed applications collect user data, 45% collect geolocation, and nearly 30% (notably Jasper, Poe, and Copilot) engage in ad tracking, meaning they cross-reference data with other services or sell it to data brokers.
Data brokers are companies specializing in buying and selling personal data. They compile information from applications, websites, and public databases to create detailed user profiles, which are then sold to advertisers, insurers, employers, and sometimes even public agencies.
Among the largest companies in this sector are Acxiom, Experian, Epsilon, and Oracle Data Cloud, which make billions of dollars exploiting this information. Despite increasing regulation in some regions, the market remains scarcely controlled globally.
According to the study, Meta AI is the only one collecting data on financial information, health, and fitness. The application doesn't stop there: it's also the only one collecting particularly sensitive information: racial or ethnic data, sexual orientation, pregnancy or childbirth information, disability, religious or philosophical beliefs, union membership, political opinions, genetic information, or biometric data.
Maud Lepetit, France manager at Surfshark, warns:
"Meta doesn't just harvest data through Facebook, Instagram, or its Audience Network. Today, they apply the same logic to their AI assistant, feeding it with public posts, photos, messages... but also data entered directly into the interface. It's a new demonstration of the potential pitfalls when generative AI relies on personal data without safeguards."
Meta AI is also the only one along with Copilot to collect user identity-related data for sharing with third parties for targeted advertising. However, with 24 types of data exploited, it stands out significantly from Copilot, which uses only two (device ID and ad data).
ChatGPT, a Moderation Strategy
OpenAI takes a more cautious approach. With only 10 types of collected data, including contact details, user content, usage and diagnostic data, ChatGPT neither uses ad tracking nor shares with third parties for commercial purposes. Moreover, the "temporary chats" option, deleted after 30 days, offers an interesting compromise between service continuity and privacy. Its users can also request OpenAI to delete their data for model training.
DeepSeek, Between Apparent Discretion and Concrete Risks
The Chinese solution DeepSeek positions itself midway with 11 types of collected data, including chat history. However, the data storage location (the People's Republic of China) and a major security breach reported by The Hacker News (leak of over a million conversation records) remind us that server location and cybersecurity practices weigh as much as the amount of collected data.
European User Data Exploited by Meta Starting This Week
While Meta will begin data collection in France and Europe as of May 27 to train its AI models, Maud Lepetit reminds:
"Unlike a human, generative AI is not accountable. It can learn anything, but it cannot unlearn. What you enter in a chatbot remains in its system, potentially forever."
If you oppose the exploitation of your personal data by Meta, you must do so before this deadline. Its approach, based on the "opt-out" principle, where the user must express refusal, rather than explicit consent ("opt-in"), raises questions about its compliance with GDPR. The legitimate interest invoked by Meta to justify this collection without prior consent has led NYOB and consumer associations to continue their actions against the company. The CNIL, for its part, considers that using legitimate interest as a legal basis for training an AI system is not illegal per se, but requires careful assessment of the interests and fundamental rights of the individuals concerned.
To better understand
What is GDPR and how does it apply to Meta AI's data collection practices?
GDPR (General Data Protection Regulation) is an EU regulation aimed at protecting individuals' personal data. It requires explicit consent ('opt-in') for data collection and use. In the case of Meta AI, which uses 'opt-out' consent, there are debates about GDPR compliance, leading to legal actions.
How is the concept of 'legitimate interest' used in personal data regulation?
Legitimate interest is a legal basis under GDPR for processing data without explicit consent. It requires companies to show that their legitimate interests do not override individuals' fundamental rights. It's a controversial basis as its application relies on a balanced assessment that can be subjective.