
TLDR : Der Konversationsassistent Meta AI ist der aufdringlichste in Bezug auf das Sammeln persönlicher Daten und übertrifft Google Gemini, laut einer Studie von Surfshark. Meta AI sammelt 32 von 35 analysierten Datentypen, einschließlich sensibler Informationen wie sexuelle Orientierung, religiöse Überzeugungen und biometrische Daten, während andere Anwendungen wie ChatGPT von OpenAI einen vorsichtigeren Ansatz verfolgen.
Inhaltsverzeichnis
Surfshark, ein Spezialist für Cybersicherheit, hat kürzlich ein Update seiner vergleichenden Studie zur Erfassung persönlicher Daten durch die führenden Chatbots auf dem Markt veröffentlicht. Die Analyse ist eindeutig: Meta AI ist der aufdringlichste Konversationsassistent. Mit 32 erfassten Datentypen von 35 analysierten übertrifft er deutlich den Durchschnitt (13 Datentypen) und liegt nun vor Google Gemini, das bisher den ersten Platz einnahm.
Seit den 2010er Jahren haben große Plattformen ihre Dominanz auf der Monetarisierung der Aufmerksamkeit aufgebaut (zielgerichtete Werbung, Empfehlungsalgorithmen). Mit dem Aufkommen der generativen KI zeichnet sich ein neues Paradigma ab: nicht mehr die Aufmerksamkeit zu fesseln, sondern direkt mit dem Benutzer in immer personalisierteren und kontextuellen Räumen zu interagieren.
Indem Meta seinen Assistenten in das Facebook/Instagram-Ökosystem integriert, überschreitet es eine Schwelle in der Datenausnutzung. Die Zustimmung des Benutzers, oft in komplexen Schnittstellen und undurchsichtigen Datenschutzrichtlinien verwässert, scheint zunehmend symbolisch.
Meta AI, der datenhungrigste
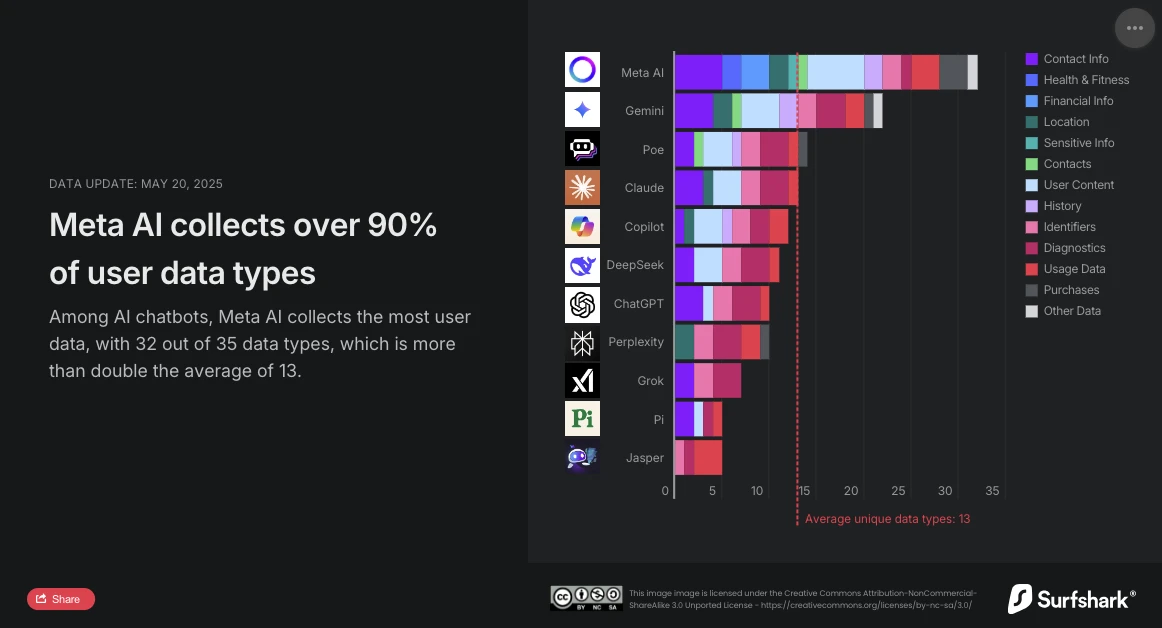
Die Studie von Surfshark hebt das Ausmaß der Datenerfassung durch KI-Chatbots hervor: Alle analysierten Anwendungen sammeln Benutzerdaten, 45 % erfassen die Geolokalisierung, und fast 30 % (darunter Jasper, Poe und Copilot) betreiben Werbetracking, das heißt, sie verknüpfen die Daten mit anderen Diensten oder verkaufen sie an Datenbroker.
Datenbroker sind Unternehmen, die sich auf den Kauf und Verkauf persönlicher Daten spezialisiert haben. Sie sammeln Informationen aus Anwendungen, Websites und öffentlichen Datenbanken, um detaillierte Benutzerprofile zu erstellen, die dann an Werbetreibende, Versicherer, Arbeitgeber und manchmal sogar an öffentliche Einrichtungen verkauft werden.
Unter den größten Unternehmen der Branche befinden sich Acxiom, Experian, Epsilon und Oracle Data Cloud, die Milliarden von Dollar durch die Ausbeutung dieser Informationen erwirtschaften. Trotz einer zunehmenden Regulierung in einigen Regionen bleibt der Markt weltweit wenig geregelt.
Laut der Studie ist Meta AI die einzige Anwendung, die Daten zu Finanzinformationen, Gesundheit und Fitness sammelt. Die Anwendung hört hier nicht auf: Sie ist auch die einzige, die besonders sensible Informationen erfasst: Rassen- oder ethnische Daten, sexuelle Orientierung, Informationen über Schwangerschaft oder Geburt, Behinderung, religiöse oder philosophische Überzeugungen, Gewerkschaftszugehörigkeit, politische Meinungen, genetische Informationen oder biometrische Daten.
Maud Lepetit, Leiterin Frankreich bei Surfshark, warnt:
"Meta begnügt sich nicht damit, Daten über Facebook, Instagram oder sein Audience Network zu sammeln. Heute wenden sie dasselbe Prinzip auf ihren KI-Assistenten an und speisen ihn mit öffentlichen Veröffentlichungen, Fotos, Nachrichten... aber auch mit den direkt in die Benutzeroberfläche eingegebenen Daten. Dies ist eine neue Demonstration der möglichen Auswüchse, wenn generative KI auf persönlichen Daten ohne Schutzmaßnahmen beruht".
Meta AI ist auch die einzige Anwendung neben Copilot, die Daten zur Benutzeridentität sammelt, um sie im Rahmen gezielter Werbung mit Dritten zu teilen. Mit 24 genutzten Datentypen unterscheidet er sich jedoch deutlich von Copilot, das nur zwei verwendet (Geräte-ID und Werbedaten).
ChatGPT, eine Strategie der Mäßigung
OpenAI verfolgt einen vorsichtigeren Ansatz. Mit nur 10 gesammelten Datentypen, darunter Kontaktdaten, Benutzerinhalte, Nutzungs- und Diagnosedaten, verzichtet ChatGPT auf Werbetracking und die Weitergabe an Dritte zu kommerziellen Zwecken. Darüber hinaus bietet die Option der "temporären Chats", die nach 30 Tagen gelöscht werden, einen interessanten Kompromiss zwischen Servicekontinuität und Datenschutz. Die Benutzer können auch OpenAI bitten, ihre Daten aus dem Training ihrer Modelle zu entfernen.
DeepSeek, zwischen scheinbarer Diskretion und konkreten Risiken
Die chinesische Lösung DeepSeek positioniert sich mit 11 gesammelten Datentypen, darunter Chat-Verlauf, im Mittelfeld. Dennoch erinnern der Speicherort der Daten (Volksrepublik China) und ein von The Hacker News gemeldeter schwerwiegender Sicherheitsverstoß (Leck von über einer Million Gesprächsaufzeichnungen) daran, dass der Standort der Server und die Cybersicherheitspraktiken ebenso wichtig sind wie die Anzahl der gesammelten Daten.
Die Daten europäischer Nutzer, von Meta ab dieser Woche genutzt
Während Meta am 27. Mai mit der Datensammlung in Frankreich und Europa zur Schulung seiner KI-Modelle beginnt, erinnert Maud Lepetit:
"Anders als ein Mensch gibt die generative KI keine Rechenschaft ab. Sie kann alles lernen, aber nichts verlernen. Was Sie in einen Chatbot eingeben, bleibt potenziell für immer in seinem System."
Wenn Sie der Nutzung Ihrer persönlichen Daten durch Meta widersprechen möchten, müssen Sie dies vor diesem Stichtag tun. Ihr Ansatz, der auf dem Prinzip des "Opt-out" basiert, bei dem der Benutzer seinen Widerspruch ausdrücken muss, anstatt auf einer ausdrücklichen Zustimmung ("Opt-in") zu beruhen, wirft Fragen bezüglich seiner Konformität mit der DSGVO auf. Das von Meta angeführte berechtigte Interesse zur Rechtfertigung dieser Sammlung ohne vorherige Zustimmung hat NYOB und Verbraucherverbände dazu veranlasst, ihre Maßnahmen gegen das Unternehmen fortzusetzen. Die CNIL ist der Ansicht, dass die Berufung auf das berechtigte Interesse als Rechtsgrundlage zur Schulung eines KI-Systems für sich genommen nicht illegal ist, jedoch eine sorgfältige Abwägung der Interessen und Grundrechte der betroffenen Personen erfordert.
Besser verstehen
Was ist die DSGVO und wie gilt sie für die Datenerhebungspraxis von Meta AI?
Die DSGVO (Datenschutz-Grundverordnung) ist eine EU-Vorschrift zum Schutz personenbezogener Daten. Sie erfordert eine ausdrückliche Zustimmung ('Opt-in') zur Datenerhebung und -nutzung. Im Fall von Meta AI, das 'Opt-out'-Zustimmung verwendet, gibt es Debatten über die DSGVO-Konformität, die zu rechtlichen Schritten geführt haben.
Wie wird das Konzept des 'berechtigten Interesses' in der Regulierung personenbezogener Daten verwendet?
Das berechtigte Interesse ist eine Rechtsgrundlage der DSGVO zur Datenverarbeitung ohne ausdrückliche Zustimmung. Es erfordert, dass Unternehmen darlegen, dass ihre berechtigten Interessen nicht die Grundrechte der Einzelpersonen überwiegen. Es ist eine umstrittene Grundlage, da deren Anwendung auf einer ausgewogenen Einschätzung basiert, die subjektiv sein kann.