
TLDR : L'assistant conversationnel Meta AI est le plus intrusif en matière de collecte de données personnelles, surpassant Google Gemini, selon une étude de Surfshark. Meta AI recueille 32 types de données sur 35 analysés, y compris des informations sensibles telles que l'orientation sexuelle, les croyances religieuses et les données biométriques, tandis que d'autres applications comme ChatGPT d'OpenAI adoptent une approche plus prudente.
目录
Surfshark,网络安全专家,最近发布了一项关于市场上主要聊天机器人的个人数据收集的比较研究更新。分析结果不容置疑:Meta AI是最具侵入性的对话助手。在35种分析的数据类型中,Meta AI收集了32种,远远超过平均水平(13种数据类型),并且现在已经超越了此前排名第一的Google Gemini。
自2010年代以来,大型平台通过注意力的货币化(定向广告、推荐算法)建立了其主导地位。随着生成式AI的兴起,新的范式正在形成:不再只是捕捉注意力,而是直接在越来越个性化和情境化的空间中与用户互动。
Meta通过将其助手整合到Facebook/Instagram生态系统中,在数据利用方面迈出了一大步。用户的同意往往被稀释在复杂的界面和不透明的隐私政策中,似乎越来越具有象征性。
Meta AI,数据的贪婪者
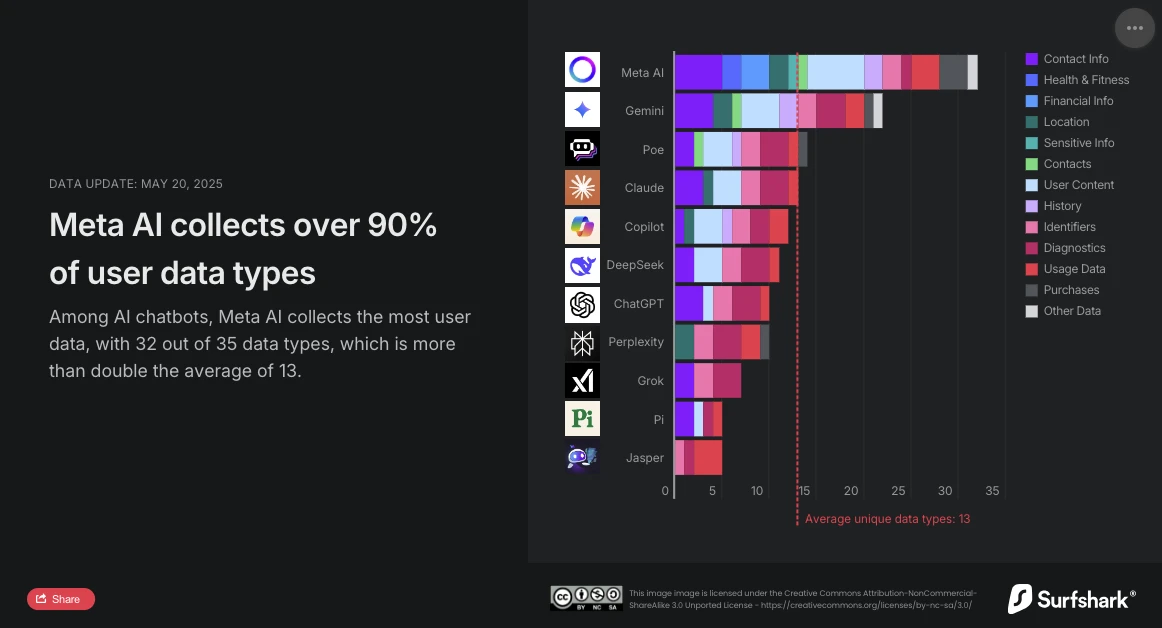
Surfshark的研究突显了聊天机器人中数据收集的广度:所有分析的应用程序都收集用户数据,45%收集地理位置,近30%(尤其是Jasper、Poe和Copilot)进行广告追踪,即将数据与其他服务的数据交叉或出售给数据经纪人。
数据经纪人是专门从事个人数据买卖的公司。他们汇编来自应用程序、网站和公共数据库的信息,以创建详细的用户档案,然后出售给广告商、保险公司、雇主,甚至有时是公共机构。
在该行业最大的一些公司中,有Acxiom、Experian、Epsilon和Oracle Data Cloud,这些公司通过利用这些信息赚取数十亿美元。尽管某些地区的监管日益增多,但全球市场仍然缺乏足够的监管。
根据研究,Meta AI是唯一收集财务信息、健康和身体状况数据的应用程序。应用程序不止于此:它也是唯一收集特别敏感信息的应用程序:种族或民族数据、性取向、怀孕或分娩信息、残疾、宗教或哲学信仰、工会会员、政治观点、基因信息或生物特征数据。
Maud Lepetit,Surfshark法国负责人,警告说:
“Meta不仅通过Facebook、Instagram或其广告网络吸取数据。如今,他们将同样的逻辑应用于其AI助手,通过公共发布、照片、消息……以及直接在界面中输入的数据来滋养它。这是生成式AI在没有防护措施的情况下依赖个人数据可能出现的偏差的新示范。”
Meta AI也是唯一一个与Copilot一起收集用户身份相关数据以便在定向广告中与第三方共享的应用程序。然而,利用24种数据类型,它显然与仅使用两种(设备ID和广告数据)的Copilot区别开来。
ChatGPT,温和策略
OpenAI采取了更谨慎的方法。只收集10种数据类型,其中包括联系信息、用户内容、使用和诊断数据,ChatGPT既不使用广告追踪也不与第三方共享用于商业目的。此外,“临时聊天”选项在30天后删除,提供了服务连续性与隐私尊重之间的有趣折中。其用户还可以请求OpenAI删除其用于模型训练的数据。
DeepSeek,表面上的谨慎与实际的风险
中国解决方案DeepSeek以收集11种数据类型(包括聊天历史记录)居中。然而,数据存储位置(中华人民共和国)和The Hacker News报告的重大安全漏洞(超过一百万条对话记录泄漏)提醒人们,服务器位置和网络安全实践与收集的数据量同样重要。
Meta自本周开始利用欧洲用户数据
正当Meta计划从5月27日起在法国和欧洲开始数据收集以训练其AI模型时,Maud Lepetit提醒说:
“与人类不同,生成式AI不负责。它可以学习任何东西,但不能遗忘。您在聊天机器人中输入的内容可能会永远保留在其系统中。”
如果您反对Meta利用您的个人数据,您必须在此截止日期前采取行动。其基于“选择退出”原则的做法,即用户必须表达拒绝意见,而不是明确同意(“选择加入”),引发了有关其是否符合GDPR的质疑。Meta引用的合法利益来证明这种未经事先同意的收集合理性,已促使NYOB和消费者协会对公司采取行动。CNIL则认为,使用合法利益作为训练AI系统的法律基础本身并不违法,但需要仔细评估相关人员的利益和基本权利。
Pour mieux comprendre
什么是GDPR,Meta AI的数据收集实践如何适用?
GDPR(通用数据保护条例)是欧盟旨在保护个人数据的法规。 它要求对数据的收集和使用提供明确的同意('选择加入')。 在使用 '选择退出' 同意的 Meta AI 的情况下,人们对 GDPR 合规性存在争议,从而导致采取法律行动。
个人数据法规中如何使用 '合法利益' 的概念?
合法利益是 GDPR 下在没有明确同意的情况下处理数据的法律依据。 它要求公司表明其合法利益不会凌驾于个人的基本权利之上。 这是一个有争议的基础,因为它的应用依赖于可以是主观的平衡评估。