在去年12月发布了其OLMO 2模型家族后,Allen Institute for Artificial Intelligence (AI2) 通过推出Tülu 3 405B继续其对开源的承诺。基于Llama 3.1,利用AI2的可验证奖励强化学习框架(RLVR),这一新模型在性能上达到或超过DeepSeek V3(其基础为DeepSeek R1)和GPT-4o,也超越了之前的同尺寸后训练模型,如Llama 3.1 405B Instruct和Nous Research的Hermes 3 405B。
优化的后训练
Tülu 3 405B的后训练配方与其前代产品Tülu 3 8B和70B相似,这些产品由AI2在去年11月发布。它包括数据的精细筛选、监督微调(SFT)、直接偏好优化(DPO)以及可验证奖励的强化学习(RLVR)。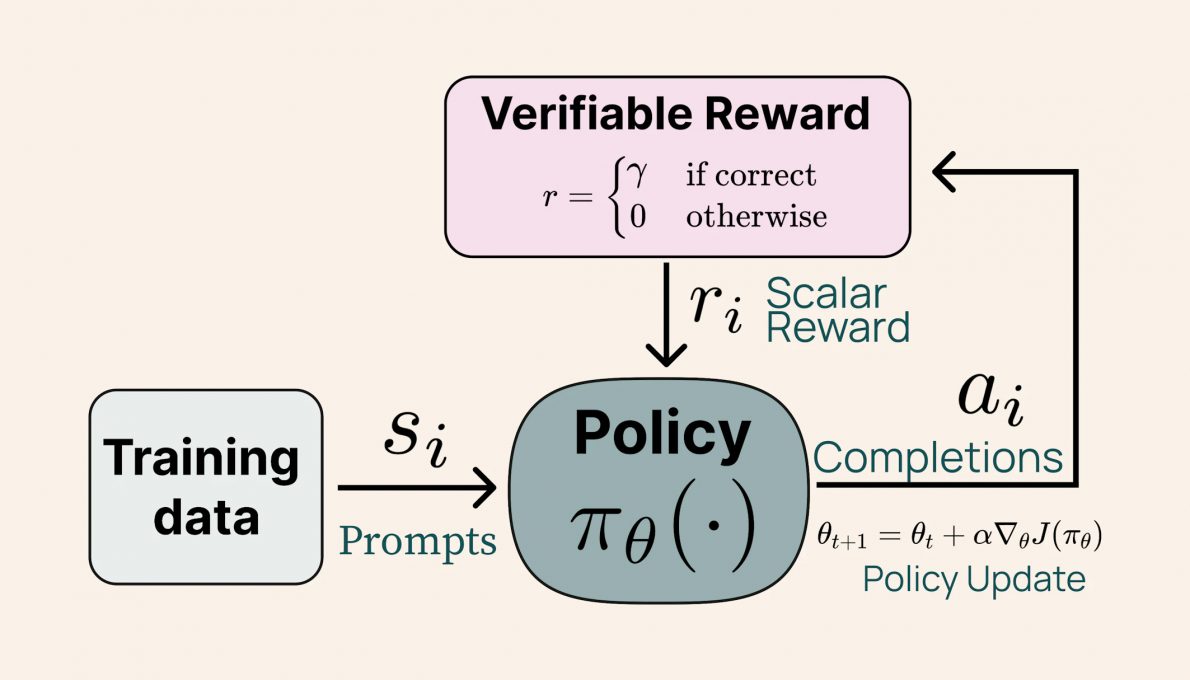 AI提供的图片。描述可验证奖励强化学习(RLVR)过程的示意图。 这种新方法显著提高了Tülu模型在解决复杂任务如数学问题解决和指令遵循方面的性能。值得注意的是,结果表明模型的规模对RLVR的有效性有正面影响:虽然较小的模型从多样化数据集训练中受益,Tülu 3 405B通过专注于更专业的数据获得了更好的性能。
AI提供的图片。描述可验证奖励强化学习(RLVR)过程的示意图。 这种新方法显著提高了Tülu模型在解决复杂任务如数学问题解决和指令遵循方面的性能。值得注意的是,结果表明模型的规模对RLVR的有效性有正面影响:虽然较小的模型从多样化数据集训练中受益,Tülu 3 405B通过专注于更专业的数据获得了更好的性能。 模型性能
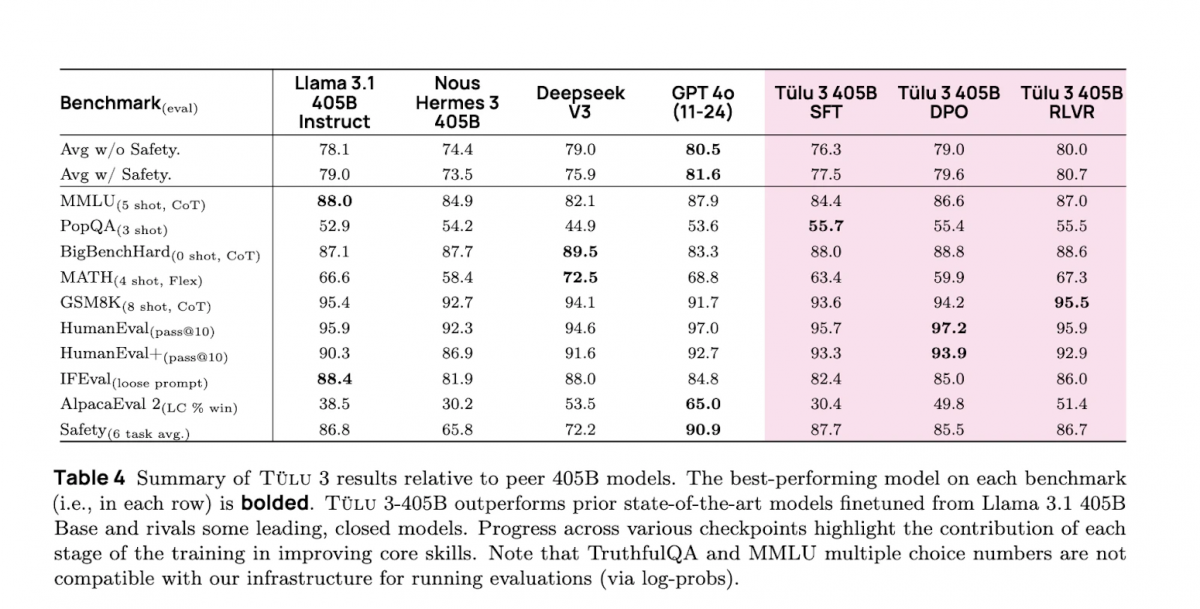
根据AI2的内部评估,Tülu 3 405B在PopQA基准测试中超过了DeepSeek V3、GPT-4o和Llama 3.1 405B,PopQA是一个包含14,000个问答对的集合,用于验证模型在信息检索和生成方面的效率。该模型还在GSM8K上取得了该类别所有模型中最高的性能,GSM8K是由OpenAI创建的一个约8,500个学校级数学问题的数据集,用于测试语言模型执行多步骤数学推理的能力。