
TLDR : ذكرت دراسة لـ Surfshark أن Meta AI هو المساعد الذكي الأكثر تدخلًا في جمع البيانات الشخصية، متجاوزًا Google Gemini. يجمع Meta AI 32 نوعًا من البيانات من أصل 35 تم تحليلها، بما في ذلك معلومات حساسة مثل التوجه الجنسي والمعتقدات الدينية والبيانات البيومترية، بينما تتبنى تطبيقات أخرى مثل ChatGPT من OpenAI نهجًا أكثر حذرًا.
المحتوى
أصدرت Surfshark، المتخصصة في الأمن السيبراني، مؤخرًا تحديثًا لدراستها المقارنة حول جمع البيانات الشخصية بواسطة chatbots الرئيسيين في السوق. التحليل لا يترك مجالًا للشك: Meta AI هو المساعد الذكي الأكثر تدخلاً. مع جمع 32 نوعًا من البيانات من أصل 35 تم تحليلها، يتجاوز بكثير المتوسط (13 نوعًا من البيانات) ويتفوق الآن على Google Gemini، الذي كان يحتل المرتبة الأولى حتى الآن.
منذ العقد الثاني من الألفية، بنت المنصات الكبرى هيمنتها على تحقيق الدخل من الانتباه (الإعلانات المستهدفة، خوارزميات التوصية). مع ظهور الذكاء الاصطناعي التوليدي، يتشكل نموذج جديد: لم يعد جذب الانتباه فحسب، بل التفاعل المباشر مع المستخدم في مساحات متزايدة التخصيص والسياق.
تخطو Meta خطوة جديدة في استغلال البيانات من خلال دمج مساعدها في منظومة Facebook/Instagram. يبدو أن موافقة المستخدم، التي غالبًا ما تكون مغمورة في واجهات معقدة وسياسات خصوصية غامضة، أصبحت رمزية بشكل متزايد.
Meta AI، الأكثر جوعًا للبيانات
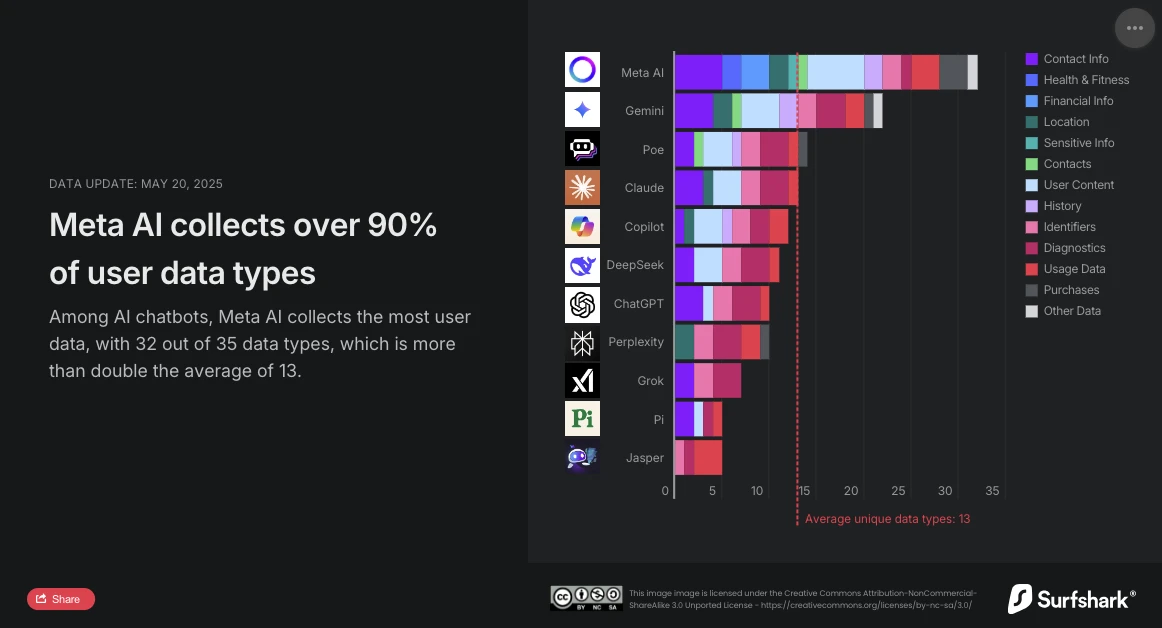
تظهر دراسة Surfshark مدى جمع البيانات بواسطة chatbots الذكية: جميع التطبيقات التي تم تحليلها تجمع بيانات المستخدمين، حيث أن 45٪ تجمع معلومات الموقع الجغرافي، وحوالي 30٪، (بما في ذلك Jasper، Poe وCopilot) تمارس التتبع الإعلاني، أي أنها تتقاطع البيانات مع تلك من خدمات أخرى أو تبيعها إلى سماسرة البيانات.
سماسرة البيانات هم شركات متخصصة في شراء وبيع البيانات الشخصية. يجمعون معلومات من التطبيقات، المواقع الإلكترونية وقواعد البيانات العامة لإنشاء ملفات تعريف مفصلة للمستخدمين، تباع بعد ذلك إلى المعلنين، شركات التأمين، أرباب العمل، وأحيانًا حتى إلى الجهات الحكومية.
من بين أكبر الشركات في هذا القطاع، نجد Acxiom، Experian، Epsilon وOracle Data Cloud، التي تتداول بمليارات الدولارات من خلال استغلال هذه المعلومات. رغم وجود تنظيم متزايد في بعض المناطق، فإن السوق لا يزال غير منظم بشكل كبير على الصعيد العالمي.
وفقًا للدراسة، يعد Meta AI الوحيد الذي يجمع البيانات حول المعلومات المالية، الصحة واللياقة البدنية. لا يتوقف التطبيق عند هذا الحد: فهو أيضًا الوحيد الذي يجمع معلومات حساسة بشكل خاص: بيانات عرقية أو إثنية، التوجه الجنسي، معلومات حول الحمل أو الولادة، الإعاقة، المعتقدات الدينية أو الفلسفية، الانتماء النقابي، الآراء السياسية، المعلومات الجينية أو البيانات البيومترية.
تحذر ماود لوبيتيت، المسؤولة عن فرنسا لدى Surfshark:
"لا تكتفي Meta بامتصاص البيانات عبر Facebook، Instagram أو Audience Network. اليوم، يطبقون نفس المنطق على مساعدهم الذكي، بتغذيته من منشورات عامة، صور، رسائل... بل أيضًا من البيانات المدخلة مباشرة في الواجهة. هذه هو عرض جديد للانحرافات الممكنة عندما يعتمد الذكاء الاصطناعي التوليدي على بيانات شخصية بدون ضوابط".
يعد Meta AI أيضًا الوحيد مع Copilot الذي يجمع بيانات تتعلق بهوية المستخدم لمشاركتها مع أطراف ثالثة في إطار الإعلان المستهدف. ومع ذلك، مع 24 نوعًا من البيانات المستغلة، يتميز بشكل كبير عن Copilot، الذي يستخدم نوعين فقط (معرف الجهاز وبيانات الإعلانات).
ChatGPT، استراتيجية الاعتدال
تتبنى OpenAI نهجًا أكثر حذرًا. مع جمع 10 أنواع فقط من البيانات، بما في ذلك البيانات الشخصية، محتوى المستخدم، بيانات الاستخدام والتشخيص، لا يلجأ ChatGPT إلى التتبع الإعلاني ولا المشاركة مع أطراف ثالثة لأغراض تجارية. بالإضافة إلى ذلك، يوفر خيار "الدردشة المؤقتة"، الذي يتم حذفه بعد 30 يومًا، حلًا وسطيًا مثيرًا بين استمرار الخدمة واحترام الخصوصية. يمكن للمستخدمين أيضًا طلب من OpenAI حذف بياناتهم لتدريب نماذجهم.
DeepSeek، بين الظاهر والواقع
تحتل الحلول الصينية DeepSeek موقعًا وسطًا مع جمع 11 نوعًا من البيانات، بما في ذلك سجل الدردشات. ومع ذلك، فإن موقع تخزين البيانات (جمهورية الصين الشعبية) وانتهاك أمني كبير تم الإبلاغ عنه من قبل The Hacker News (تسريب أكثر من مليون تسجيل للمحادثات) يذكر أن موقع الخوادم وممارسات الأمن السيبراني لهما نفس الأهمية مثل عدد البيانات المجمعة.
استغلال بيانات المستخدمين الأوروبيين من قبل Meta اعتبارًا من هذا الأسبوع
بينما تستعد Meta لبدء جمع البيانات في فرنسا وأوروبا اعتبارًا من 27 مايو لتدريب نماذجها الذكية، تذكر ماود لوبيتيت:
"على عكس الإنسان، لا تقدم الذكاء الاصطناعي التوليدي حسابًا. يمكنها تعلم أي شيء، ولكنها لا تستطيع التعلم. ما تدخله في chatbot يبقى في نظامه، ربما إلى الأبد".
إذا كنت تعارض استغلال بياناتك الشخصية من قبل Meta، فيجب عليك القيام بذلك قبل هذا الموعد النهائي. طريقتها، التي تعتمد على مبدأ "opt-out", حيث يجب على المستخدم التعبير عن رفضه، بدلاً من موافقة صريحة ("opt-in")، تثير تساؤلات حول توافقها مع GDPR. المصلحة الشرعية التي تذكرها Meta لتبرير هذا الجمع بدون موافقة سابقة، دفعت NYOB وجمعيات المستهلكين لمواصلة الإجراءات ضد الشركة. تعتبر CNIL أن اللجوء إلى المصلحة الشرعية كأساس قانوني لتدريب نظام AI ليس غير قانوني في ذاته، ولكنه يتطلب تقييمًا دقيقًا للمصالح والحقوق الأساسية للأشخاص المعنيين.
لتحسين الفهم
ما هو <span dir="ltr">RGPD</span> وكيف ينطبق على ممارسات جمع البيانات بواسطة <span dir="ltr">Meta AI</span>؟
<span dir="ltr">RGPD (Regulation General of Data Protection)</span> هو تنظيم للاتحاد الأوروبي يهدف إلى حماية البيانات الشخصية للأفراد. يتطلب موافقة صريحة ('<span dir="ltr">opt-in</span>') لجمع واستخدام البيانات. في حالة <span dir="ltr">Meta AI</span>، الذي يستخدم الموافقة عن طريق '<span dir="ltr">opt-out</span>'، هناك نقاشات حول الامتثال لل<span dir="ltr">RGPD</span>، مما أدى إلى اتخاذ إجراءات قانونية.
كيف يتم استخدام مفهوم "المصلحة المشروعة" في تنظيم البيانات الشخصية؟
المصلحة المشروعة هي أساس قانوني ضمن <span dir="ltr">GDPR</span> لمعالجة البيانات بدون موافقة صريحة. يتطلب الأمر من الشركات إظهار أن مصالحها المشروعة لا تتجاوز الحقوق الأساسية للأفراد. إنه أساس مثير للجدل حيث أن تطبيقه يعتمد على تقييم متوازن يمكن أن يكون ذاتيًا.