En bref : L'assistant conversationnel Meta AI est le plus intrusif en matière de collecte de données personnelles, surpassant Google Gemini, selon une étude de Surfshark. Meta AI recueille 32 types de données sur 35 analysés, y compris des informations sensibles telles que l'orientation sexuelle, les croyances religieuses et les données biométriques, tandis que d'autres applications comme ChatGPT d'OpenAI adoptent une approche plus prudente.
Surfshark, spécialiste en cybersécurité, a récemment publié une mise à jour de son étude comparative sur la collecte de données personnelles par les principaux chatbots du marché. L’analyse est sans appel : Meta AI est l’assistant conversationnel le plus intrusif. Avec 32 types de données collectées sur les 35 analysées, il dépasse largement la moyenne (13 types de données) et devance désormais Google Gemini, qui occupait jusqu’alors la première place.
Depuis les années 2010, les grandes plateformes ont bâti leur domination sur la monétisation de l’attention (publicité ciblée, algorithmes de recommandation). Avec l’avènement de l’IA générative, un nouveau paradigme se dessine : non plus capter l’attention, mais interagir directement avec l’utilisateur dans des espaces de plus en plus personnalisés et contextuels.
Meta, en intégrant son
assistant à l’écosystème Facebook/Instagram, franchit un seuil dans l'exploitation des données. Le consentement de l'utilisateur, souvent dilué dans des interfaces complexes et des politiques de confidentialité opaques, semble de plus en plus symbolique.
Meta AI, le plus gourmand en données
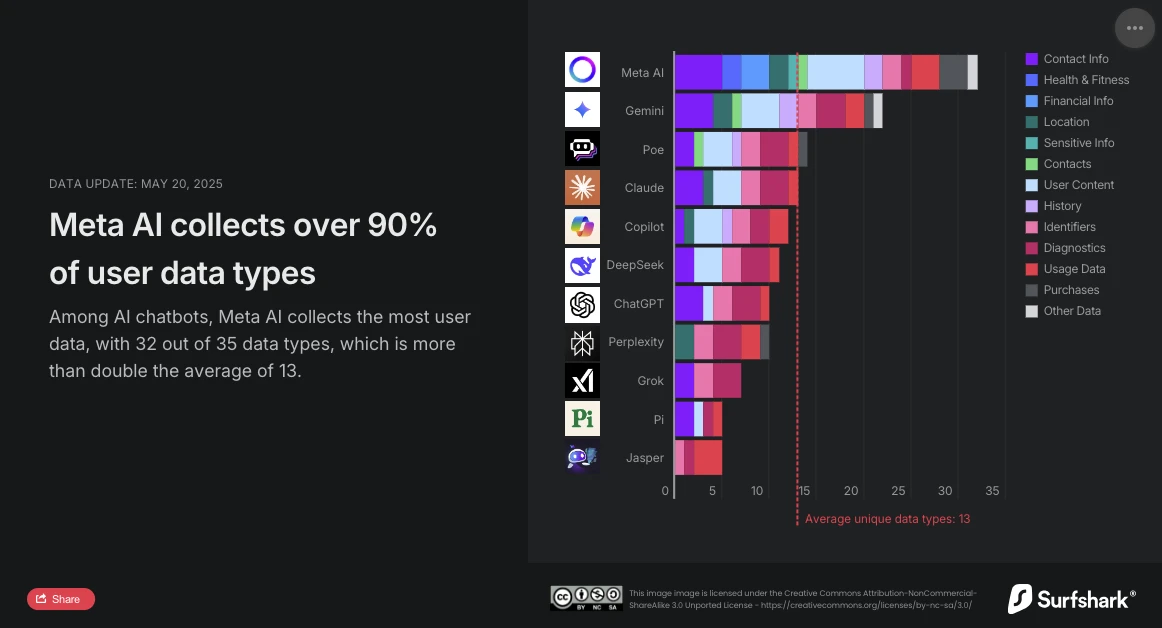
L’étude de
Surfshark met en évidence l’ampleur de la collecte de données par les chatbots IA : toutes les applications analysées collectent des données utilisateur, 45 % recueillent la géolocalisation, et près de 30 %, (notamment Jasper, Poe et Copilot) pratiquent le tracking publicitaire, c’est-à-dire qu’elles croisent les données avec celles d’autres services ou les revendent à des data brokers.
Les data brokers sont des entreprises spécialisées dans l’achat et la vente de données personnelles. Elles compilent des informations issues des applications, sites web et bases de données publiques afin de créer des profils détaillés des utilisateurs, revendus ensuite à des
annonceurs, assureurs, employeurs, et parfois même à des organismes publics.
Parmi les plus grandes sociétés du secteur, on trouve Acxiom, Experian, Epsilon et
Oracle Data Cloud, qui brassent des milliards de dollars en exploitant ces informations. Malgré une réglementation croissante dans certaines régions, le marché reste peu encadré à l’échelle mondiale.
Selon l’étude,
Meta AI est le seul à collecter des données sur les informations financières, la santé et la forme
physique. L'application ne s'arrête pas là : elle est également la seule à collecter des informations particulièrement sensibles : données raciales ou ethniques, orientation sexuelle, informations sur la grossesse ou l’accouchement,
handicap, croyances religieuses ou philosophiques, appartenance syndicale, opinions politiques, informations génétiques ou données biométriques.
"Meta ne se contente pas d’aspirer les données via Facebook, Instagram ou son Audience Network. Aujourd’hui, ils appliquent la même logique à leur assistant IA, en le nourrissant de publications publiques, de photos, de messages… mais aussi des données saisies directement dans l’interface. C’est une nouvelle démonstration des dérives possibles quand l’IA générative repose sur des données personnelles sans garde fous".
Meta AI est également le seul avec Copilot à collecter des données liées à l’identité de l’utilisateur pour les partager avec des tiers dans le cadre de la publicité ciblée. Cependant, avec 24 types de données exploitées, il se distingue nettement de Copilot, qui n’en utilise que deux (ID d’appareil et les données publicitaires).
ChatGPT, une stratégie de modération
OpenAI adopte une approche plus prudente. Avec seulement 10 types de données collectées, parmi lesquelles les coordonnées, le contenu de l’utilisateur, les données d’usage et de diagnostic, ChatGPT ne recourt ni au suivi publicitaire ni au partage avec des tiers à des fins commerciales. De plus, l’option des "chats temporaires", supprimés après 30 jours, offre un compromis intéressant entre continuité de service et respect de la vie privée. Ses utilisateurs peuvent également demander à OpenAI la suppression de leurs données pour l'entrainement de ses modèles
DeepSeek, entre discrétion apparente et risques concrets
La solution chinoise DeepSeek se positionne à mi-chemin avec 11 types de données collectées, dont l’historique des chats. Toutefois, le lieu de stockage des données (la République populaire de
Chine) et une violation de sécurité majeure rapportée par The Hacker News ( fuite de plus d’un million d’enregistrements de conversations) rappellent que la localisation des serveurs et les pratiques de cybersécurité pèsent tout autant que le nombre de données collectées.
Les données des utilisateurs européens exploitées par Meta dès cette semaine
Alors que
Meta va débuter sa collecte de données en
France et en
Europe dès ce 27 mai pour entraîner ses modèles d'IA, Maud Lepetit rappelle :
"Contrairement à un humain, l’IA générative ne rend pas de comptes. Elle peut apprendre n’importe quoi, mais elle ne peut pas désapprendre. Ce que vous saisissez dans un chatbot reste dans son système, potentiellement pour toujours".
Si vous vous opposez à l'exploitation de vos données personnelles par
Meta, vous devez le faire avant cette date butoir. Sa démarche, qui repose sur le principe de l'« opt-out », où l'utilisateur doit exprimer son refus, plutôt que sur un consentement explicite (« opt-in »), soulève des questions quant à sa conformité avec le RGPD. L'intérêt légitime invoqué par Meta pour justifier c ette collecte sans consentement préalable, a amené NYOB et des associations de
consommateurs à poursuivre leurs actions contre l'entreprise. la
CNIL, quant à elle, estime que le recours à l'intérêt légitime comme base légale pour entraîner un système d'IA n'est pas illégal en soi, mais nécessite une évaluation attentive des intérêts et droits fondamentaux des personnes concernées .
Pour mieux comprendre (assisté par l'IA)
Qu'est-ce que le RGPD et comment s'applique-t-il aux pratiques de collecte de données par Meta AI ?
Le RGPD (Règlement Général sur la Protection des Données) est une réglementation de l'Union Européenne visant à protéger les données personnelles des individus. Il exige un consentement explicite ('opt-in') pour la collecte et l'utilisation de données personnelles. Dans le cas de Meta AI, qui utilise le consentement par 'opt-out', il y a des débats sur la conformité au RGPD, ce qui a conduit à des actions en justice.
Comment le concept de 'l'intérêt légitime' est-il utilisé dans la réglementation des données personnelles ?
L'intérêt légitime est un des fondements légaux du RGPD pour le traitement des données sans consentement explicite. Il nécessite que l'entreprise démontre que ses intérêts légitimes ne sont pas en conflit avec les droits fondamentaux de la personne. C'est une base légale controversée, car son application repose sur une évaluation équilibrée qui peut être subjective.
